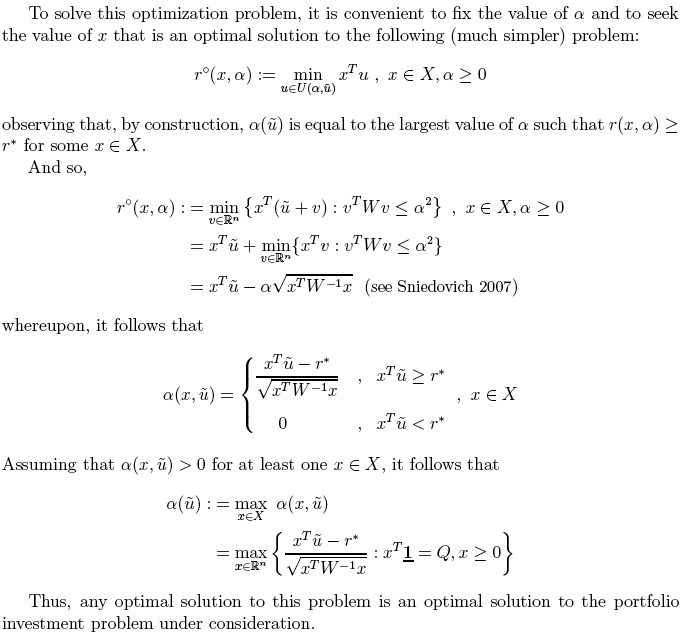At the end of 2006 I launched a campaign to contain the spread of Info-Gap decision theory in Australia. I took this radical step because I am convinced that Info-Gap decision theory is fundamentally flawed. In fact, this theory is the best example of a classic voodoo decision theory I know. The compilation of FAQs about this theory posted here is part of my campaign.
In case you are unfamiliar with it, my criticism of Info-Gap Decision Theory is now well documented in many articles and presentations, including
The harshness is proportional to the severity of the flaws in Info-Gap Decision Theory and the level of promotion that it receives in Australia and elsewhere, for instance the AEDA 5-day workshop on Info-Gap Applications in Ecological Decision Making (University of Queensland, September 15-19, 2008).
The degree of harshness often increases in response to additional misguided arguments put forward by Info-Gap proponents in repeated futile attempts to explain the basic flaws. For instance the repeated misguided futile attempts to explain why Info-Gap's robustness model is not a Maximin model.
The questions about Info-Gap Decision Theory that I take up on this page go to the heart of this theory: its characteristic features, mode of operation, capabilities etc. Hence, they bear directly on its validity and the justification (in fact lack thereof) for using it and should therefore be of interest to those who use/promote this theory, as well as to those who contemplate using/promoting it.
I have assembled this set of questions over the past five years and have in fact discussed them in various forums: conferences, workshops, informal discussions, articles, web site. Still, I do not presume that I have thus anticipated all the questions that might be raised about this topic. So, if after reading this discussion you may still have questions about Info-Gap Decision Theory that are not dealt with here, feel free to communicate them to me and I shall gladly add them to the current list.
However, before you do this, please check the list of FAQs on my agenda.
Note that the focal point of this theory is a -- rather simple -- mathematical model. This means of course that many of the questions that Info Gap gives rise to are technical in nature and must therefore be given a quantitative treatment. Still, some of the truly important questions about this theory -- those that expose its failure -- are not technical, but rather conceptual, and can be described graphically.
Also note that this is an on-going, long-term, work-in-progress, project. So, I do not have a completion date in mind.
Remarks:
Unless otherwise stated, the term "Info-Gap" is used here (as in all my other writings on this topic) as short-hand for "Info-Gap Decision Theory", the theory put forward in Ben-Haim(2001, 2006).
The mathematical notation I use here is similar, but not identical, to that used in Ben-Haim (2001, 2006). In particular, here I use d to denote the decision variable and D to denote the decision space, whereas Ben-Haim (2001, 2006) uses q and Q, respectively, for this purpose. Thus, Info-Gap's generic robustness model is as follows:
α(d,û):= max {α≥0: r(d,u) ≥ r*, ∀u∈U(α,û)} , d∈D
where:
D = the set of decisions available to the decision maker.
u = possible value of the parameter of interest. The true value is subject to severe uncertainty.
û = estimate of the true value of u.
r(d,u) = reward generated by decision d if the true value of the parameter of interest is equal to u.
r* = critical level of reward.
U(α,û) = region of uncertainty of size α centered at û.
α(d,û) = robustness of decision d given that the estimate is û.
Note that contrary to the practice in the Info-gap literature, I write α(d,û) rather than α(d,r*), to emphasize the central role that the estimate plays in Info-Gap decision theory.
It is assumed that û satisfies the performance requirement for all d∈D, that is, r(d,û)≥r*,∀d∈D. This is just a technicality, as if r(d,û)<r* for some decision d, then this decision can be removed from D at the outset.
I use the term complete region of uncertainty to designate the region of uncertainty that contains all the regions of uncertainty around the estimate generated by Info-Gap's uncertainty model. Symbolically, the complete region of uncertainty, call it U, is some set that contains U(α,û) for all α≥0. This set can be, for example, the limit of U(α,û) as α → ∞ if such a limit exists. Note that Info-Gap decision theory allows U to be unbounded, but U is not required to be unbounded. Here is the picture:
In this case U is bounded.
My objective is to make this discussion accessible to the widest readership possible, hence the mathematical discourse is kept to the barest minimum. References are provided for readers with an interest in the more mathematically oriented treatments of the relevant topics.
The questions:
The FAQs and the answers are listed in the order in which they were composed. For your convenience a subject classification is also provided.
Can't Info-Gap's "localness" flaw be fixed by means of a robustness analysis at a number of different estimates spread over the complete region of uncertainty?
Answer-1: Info-Gap Decision Theory -- as described by its founder Ben-Haim (2001, 2006) -- is a non-probabilistic decision theory designed expressly to provide a methodology for robust decision-making under conditions of severe uncertainty.
It is important to take note that the key factor here is severe uncertainty. That is, "severe uncertainty" is Info-Gap's overriding concern. This is brought out by the subtitles of both editions of the Info-Gap book (Ben-Haim, 2001, 2006). Indeed, every effort is made in these books (and in other publications) to put across the severity (depth, profundity, forbidding nature) of the uncertainty which Info-Gap takes on. Thus, to convey the daunting nature of the uncertainty it is usually summed up in the epithet ""Knightian Uncertainty".
In Ben-Haim's (2007, p.2) own words:
" ... Info-gap theory is useful precisely in those situations where our best models and data are highly uncertain, especially when the horizon of uncertainty is unknown. In contrast, if we have good understanding of the system then we don't need info-gap theory, and can use probability theory or even completely deterministic models. It is when we face severe Knightian uncertainty that we need info-gap theory. ..."
See FAQ-7 for details regarding the meaning of "severe uncertainty" within the framework of Info-Gap decision theory.
FAQ-2: On what grounds do you claim that Info-Gap Decision Theory is fundamentally flawed?
Answer-2: I claim that Info-Gap Decision Theory is fundamentally flawed because ... it is obviously fundamentally flawed.
To give a full account of my claim that Info-Gap Decision Theory is fundamentally flawed I will have to go into a number of issues whose clarification will reveal the errors, misconceptions, mistakes etc. that this theory is riddled with. These issues are discussed in detail below in the answers to some of the other questions.
However, to give you an immediate sense of how flawed the thinking pervading this theory is, consider this:
rumor ---->
Info-Gap Robustness Model
----> robust decision
If you are mystified by the idea that a scientific theory can seriously advance a thesis such as the one encapsulated by this picture let me remind you of Info-Gap's prescription for tackling severe uncertainty.
To tackle problems subject to severe uncertainty, Info-Gap puts forward a mathematical model that uses an estimate of the parameter of interest as the vital input required for determining the robustness of decisions. Considering that the true value of the parameter of interest is subject to severe uncertainty, Info-Gap openly admits that this estimate can be no better than a wild guess, or even a rumor.
Yet at the same time, it contends that the results generated by this model are reliable, indeed robust. In other words, the theory openly violates the universal maxim that the results generated by a model can be only as good as the estimates on which the model is based.
Clearly, a theory advancing such an idea must be deemed fundamentally flawed, unless of course it can formally show how a model using a "rumor" or a "wild guess" as input, is capable of transforming this input into reliable results, namely robust decisions.
Info-Gap decision theory is completely oblivious to this fundamental requirement.
This is precisely why I regard info-Gap decision theory as a classic example of a voodoo decision theory (see FAQ-6).
FAQ-3: How is it that you are the only analyst who claims that Info-Gap is so flawed?
Answer-3: Of course on this I can only speculate, citing Galileo Galilei's (1564-1642) famous remark:
In matters of science, the authority of thousands is not worth the humble reasoning of one single person.
What I can say though is that although I was the first analyst to criticize Info-Gap decision theory formally "in public", there are others who share my critical views on this theory.
The trouble is, however, that unless other analysts openly join my campaign it will be difficult to stop this flawed theory in its tracks.
FAQ-4: In what sense is Info-Gap's robustness model radically different from existing classic models of robustness?
Answer-4: Info-Gap proponents mistakenly hold that this theory is radically different from other decision theories, attributing its difference to Info-Gap's uncertainty model being non-probabilistic.
For instance, here is how this thesis is presented (emphasis is mine) in Ben-Haim (2006):
Info-gap decision theory is radically different from all current theories of decision under uncertainty. The difference originates in the modeling of uncertainty as an information gap rather than as a probability. The need for info-gap modeling and management of uncertainty arises in dealing with severe lack of information and highly unstructured uncertainty.
Ben-Haim (2006, p. xii)
and
In this book we concentrate on the fairly new concept of information-gap uncertainty, whose differences from more classical approaches to uncertainty are real and deep. Despite the power of classical decision theories, in many areas such as engineering, economics, management, medicine and public policy, a need has arisen for a different format for decisions based on severely uncertain evidence.
Ben-Haim (2006, p. 11)
Of course, this is a gross error as classical decision theory does indeed offer non-probabilistic models for the management of severe uncertainty. For instance, Wald's famous Maximin model (circa 1945) is a case in point.
This error is further compounded in Ben-Haim's (2001, 2006) failure to recognize that Info-Gap's robustness model is in fact a simple instance of Wald's Maximin model.
This point is explained in detail in the answers to the FAQs dealing with the relationship between Info-Gap's robustness model and Wald's Maximin model (see FAQ-20, FAQ-21, FAQ-22).
FAQ-5: On what grounds do you claim that Info-Gap's robustness model is not new?
Answer-5: My claim that Info-Gap's robustness model is not new is substantiated by a theorem showing that this model is a simple instance of Wald's famous Maximin model (1945).
This point is explained in detail in the answers to the FAQs about the relationship between Info-Gap's robustness model and Wald's Maximin model (see FAQ-20, FAQ-21, FAQ-22).
Answer-6: My claim that Info-Gap's decision theory is a voodoo decision theory is based on the simple fact that this theory violates the Garbage In -- Garbage Out Maxim.
To elaborate, in the world of science the ruling convention is that bad input is unlikely to produce good
output. This is an indisputable fundamental of sound scientific reasoning dictating that a model input with garbage (eg. questionable estimates that are likely to be substantially wrong ) is --methodologically speaking -- unlikely to generate reliable results.
Indeed, any claim to the contrary, attributing reliability to results obtained under such conditions would require uncontestable proof, demonstration, or at least a cogent explanation.
In a nutshell then, to contend -- without a "proof" -- that:
As this is the type of thinking that underlines the mathematical model put forward by Info-Gap Decision Theory, I regard this theory a voodoo decision theory.
Answer-7: The point to note here is that other than discoursing at length on the forbidding nature of the uncertainty that Info-Gap decision theory is designed for, the theory does not give the concept "severe uncertainty" a formal definition.
Instead, it makes certain working assumptions regarding the modeling of conditions of severe uncertainty. Thus, one of its key assumptions is that -- given the severe uncertainty -- the estimate û utilized by Info-Gap's uncertainty model is of doubtful quality. In other words, it postulates that our estimate of the true value of the key parameter of interest is a wild guess and is likely to be substantially wrong.
Of course, this working assumption regarding the meaning of "severe uncertainty" in the context of Info-Gap's model is perfectly sensible so that it cannot be faulted.
Answer-8: Info-Gap decision theory defines robustness as the "size" of the largest region of uncertainty around a given estimate of the parameter of interest such that a given performance requirement is satisfied at every point in this region.
The following picture illustrates this idea.
Explanation
The small black dot represents the estimate of the parameter of interest.
The large circle represents the complete region of uncertainty under consideration.
The true value of the parameter is somewhere in this circle.
Each small white circle represent a region of uncertainty centered at the estimate whose size is the radius of the circle.
The largest white circle is the largest "safe" region of uncertainty around the estimate.
The given performance requirement is satisfied at every point in this "safe" circle.
Any larger circle centered at the estimate is not "safe" in that it contains at least one point where the performance requirement is not satisfied.
Informally then, in this case robustness is the size (radius) of the largest "completely safe" region of uncertainty (circle) around the estimate. Note that a region of uncertainty (circle) is said to be "completely safe" if every point in this circle satisfies the performance requirement.
FAQ-9:What are the main ingredients of an Info-Gap decision-making model?
Answer-9: A complete Info-Gap decision model consists of five basic objects:
Decision space: The set of decisions available to the decision-maker. We let D denote this set and let d denote its generic element (decision).
Uncertainty space: A set that contains the true (unknown) value of the parameter of interest. We let U denote this set and let u denote its generic element.
Estimate: An estimate of the true value of the parameter of interest. We let u* denote the true value of u and let û denote our estimate of this value. It is assumed that u* and û are elements of U.
Regions of uncertainty: A nested family of subsets of the complete region of uncertainty U, all "centered" at the estimate û. We let U(α,û) denote the region of uncertainty of "size" α centered at û. Here α is a non-negative number representing the "size" of the region U(α,û). These regions are defined in such a way that U(α,û) is non-decreasing with α.
Performance requirement: This is a constraint that stipulates whether a value of the parameter in the uncertainty space is "safe" with respect to a given decision. Typically, this requirement is specified by two objects: a real valued function r=r(d,u) and a critical level of performance r*. The requirement would then be either r(d,u) ≤ r* or r(d,u) ≥ r*.
The problem that a model consisting of these objects represents is roughly as follows: select from D the most robust decision with respect to the performance constraint and the regions of uncertainty under consideration.
A more formal description of the decision problem under consideration is given in the answer to FAQ-12.
Answer-10: Info-Gap's uncertainty model consists of the following objects, all of which are on the list discussed in FAQ-9:
Info-Gap's Uncertainty Model
The uncertainty space, U, represents the set containing the true (unknown) value of the parameter of interest. In the picture this set is represented by the large circle. This set is allowed to be unbounded.
The estimate, û, of the true value of the parameter of interest. This is the point represented by the black dot in the picture.
A family of nested subsets of U, representing nested regions of uncertainty around the estimate. Here U(α,û) represents a region of uncertainty of "size" α centered at û. It is assumed that U(0,û)={û} and that U(α,û) is non-decreasing with α, namely U(α,û) is a subset of U(α+ε,û) for all positive values of α and ε.
In the picture the regions of uncertainty are circles and the "size" of a region is the radius of the circle representing the region.
Remarks:
The complete region of uncertainty, namely the uncertainty space U, can be viewed as the limit of the region U(α,û) as its size α goes to infinity. Formally, it can be any set that contains U(α,û) for all α ≥ 0.
Interestingly, but not surprisingly, and contrary to my own practice, the Info-Gap literature rarely makes an explicit reference to the complete region of uncertainty U. Namely, U is often neglected to be stipulated in the formulation of the Info Gap model. This is a most unfortunate practice because the first question that you must ask yourself when you model a problem subject to severe uncertainty is: what is the uncertainty space U that I try to model?
Another unfortunate consequence of this bad practice is that some Info-Gap users labor under the erroneous impression that Info-Gap's uncertainty model has no "complete region of uncertainty". I therefore urge these misguided Info-Gap users to take a closer look at Ben-Haim (2006, p. 31), where this region (space) is noted, albeit not as explicitly as it should have been.
FAQ-11:What is Info-Gap's generic robustness model?
Answer-11: Info-Gap's robustness model defines the robustness of a decision. The following is Info-Gap's generic robustness model:
α(d,û):= max {α≥0: r(d,u) ≥ r*, ∀u∈U(α,û)} , d∈D
In words, the robustness of decision d is the size of the largest region of uncertainty U(α,û) such that the performance requirement r(d,u) ≥ r* is satisfied for all u in U(α,û).
I use the term "generic" here to indicate that there are variations on this theme. For instance,
α(d,û):= max {α≥0: r(d,u) ≤ r*, ∀u∈U(α,û)} , d ∈ D
is also a typical Info-Gap robustness model, the difference being in the sign of the performance constraint.
Note that the two models are equivalent: one can be derived from the other simply by multiplying the performance constraint by -1 and remembering to reverse the sign ...
FAQ-12:What is Info-Gap's generic decision-making model?
Answer-12: Info-Gap's decision-making model defines the optimal decisions. It states that the best (optimal) decision is that whose robustness is at least as large as that of any other decision:
α(û) :=
max
α(d,û)
d∈D
More explicitly,
α(û) =
max
max {α≥0: r(d,u) ≥ r*, ∀u∈U(α,û)}
d∈D
Note that the inner max is superfluous in the sense that it can be incorporated in the outer max, hence,
α(û) =
max
{α: r(d,u) ≥ r*, ∀u∈U(α,û)}
d∈D
α≥0
This means that both mathematically and conceptually, in the framework of Info-Gap's robustness and decision-making models the parameter α is a control (decision) variable.
FAQ-13:In what sense is Info-Gap's robustness model inherently local?
Answer-13: Info-Gap's robustness model is inherently local in the accepted meaning of this term (eg. optimization). It defines robustness in reference to the performance of decisions in the neighborhood of the estimate û.
This means that, methodologically, the analysis makes no attempt to investigate how the performance requirement fares outside the estimate's neighborhood. The analysis probes away from the estimate no further than the violation of the performance requirement allows.
This is a direct consequence of the nesting property of the regions of uncertainty. If the performance requirement is violated at some point u' in U(α',û) for some α'≥0, then the nesting property implies that for any α≥α' the requirement is also violated at some point in U(α,û).
FAQ-14:What is the significance of the local nature of Info-Gap's robustness model?
Answer-14: The significance of the local nature of Info-Gap's robustness model is that, methodologically, it determines the robustness of decision d, namely the value of α(d,û), only on the basis of the performance of d on U(α(d,û),û).
In other words, the value of α(d,û) does not represent the performance of decision d outside the region U(α(d,û),û).
The following picture illustrates this important fundamental property of Info-Gap's robustness model:
Info-Gap's No Man's Land
The large rectangle represents the compete region of uncertainty, U.
α' is the robustness of some decision d, namely α' =α(d,û) for some d∈D.
ε is some small positive constant.
So by definition, d satisfies the performance requirement at every point in U(α',û).
By definition, d violates the performance constraint at least in one point in U(α'+ε,û).
Hence, the area outside U(α'+ε,û) is a No Man's Land: the robustness of d is totally unaffected by how well/badly d performs outside U(α'+ε,û).
Therefore, if U(α+ε,û) is relatively much smaller than U, the robustness of d as determined by Info-Gap's robustness model, namely α', does not represent how well/badly d performs over the complete region of uncertainty U.
The adverse effect of this congenital property of Info-Gap's robustness model is that it is, in principle, unable to yield a correct evaluation of the robustness of decisions relative to the complete region of uncertainty.
For example, consider this simple case:
The two decisions, x and y, have -- according to Info-Gap -- the same robustness, which is equal to the radius of the shown circle around the estimate. Yet, the "safe" region of decision y is much larger than the "safe" region of decision x, where -- as usual -- the term "safe" refers to the subset of the complete region of uncertainty on which the given decision satisfies the performance requirement.
FAQ-15:What is the fundamental flaw in Info-Gap's uncertainty model?
Answer-15: The fundamental flaw in Info-Gap's uncertainty model is that its regions of uncertainty, namely the sets U(α,û), α≥0, are, as matter of principle, unable to properly represent all the relevant subsets of the complete region of uncertainty U.
To illustrate, consider the case where the complete region of uncertainty is the real line, namely U=(-∞,∞), and the estimate is û=0.
In this case the region U(α,û) would be an interval say, U(α,û) =[a(α),b(α)], containing û=0, whose end points depend on α.
The trouble here is that such a scheme is unable to generate a subset of U=(-∞,∞) that is not a continuous interval of the real line containing the origin û=0.
For example, suppose that U(α,û)=[-α,α]. Then this scheme cannot generate a subset of U such as the union of the intervals [-1,1], [300,768], and [10000,∞). The point of course is that such sets may represent intervals on which a given decision satisfies the performance constraint.
So, the fact that Info-Gap's analysis is unable to generate subsets of U that are not "simple" neighborhoods of the estimate û brings out how deleterious the fundamental failing of Info Gap is.
In a nutshell:
Under severe uncertainty the estimate û is a wild guess, a poor indication of the true value of the parameter of interest and is likely to be substantially wrong.
This means that it is highly unlikely that the true value of u will be in the immediate neighborhood of the estimate û.
It follows, therefore, that it is essential to employ uncertainty models that are capable of generating subsets of the complete region of uncertainty that properly represent or, in the very least, approximate this complete region.
The fact that Info-Gap's uncertainty model takes no notice whatsoever of this crucial issue reveals how profoundly flawed it is.
FAQ-16:What is the fundamental flaw in Info-Gap's generic robustness model?
Answer-16: The fundamental flaw in Info-Gap's robustness model is that it makes a mockery of Info-Gap's declared aim: the tackling of severe uncertainty. That is, in stark contradiction to this declared aim, Info-Gap's robustness model in effect ignores the severity of the uncertainty altogether.
This fact is vividly brought out by the following bizarre Invariance Property of Info-Gap's robustness model. Specifically, the robustness of a decision, say d, is completely invariant with the size of the complete region of uncertainty U, so long as U contains the region U(α',û) where α'> α(d,û).
To illustrate, suppose that for some decision d we find that α(d,û) = 1000 and that U contains the region U(1001, û). Then this implies that the robustness of d will remain equal to 1000 regardless of U increasing in size.
This is illustrated by the following figure:
Note that the robustness of the decision remains unchanged despite the complete region of uncertainty growing from U' to U'', to U''' and so on.
Clearly, this is absurd.
All that is left to say is that only a theory that completely ignores the severity of the uncertainty under consideration can put forward a robustness model possessing such a bizarre property.
FAQ-17:What is the fundamental flaw in Info-Gap's decision-making model?
Answer-17: The combined effect of all the ills plaguing Info-Gap is that the Info-Gap decision-making model in effect provides a thoroughly distorted evaluation of decisions. Indeed, what else can be expected of a model that determines how good/poor a decision is solely on grounds of the behavior of the performance requirement in the neighborhood of an estimate of the parameter of interest?!
Thus, Info-Gap's decision-making model is thoroughly oblivious to the following pathologic situations that it systematically gives rise to: there can be a pair of decisions, say (d',d''), such that
d' performs well in the immediate neighborhood of the estimate û.
d' performs extremely poorly elsewhere in the complete region of uncertainly.
d'' performs not so well in the immediate neighborhood of the estimate û.
d'' performs extremely well elsewhere in the complete region of uncertainly.
This means of course that using Info-Gap's robustness model as a methodology for decision-making under severe uncertainty, the decision maker is instructed to prefer d' over d'' even if the complete region of uncertainty is much larger than U(α',û), where α'=α(d',û) and the value of the estimate û is based on ... rumors.
To illustrate this issue consider the following example, constructed by Daphne Do, my honors student (2008).
Assume that two decisions, d' and d'', have exactly the same robustness as determined by Info-Gap. The large rectangle represents the complete region of uncertainty and the shaded areas represent the "safe" regions of uncertainty, namely the regions over which the decisions satisfy the performance requirement. The circles represent Info-Gap's regions of uncertainty of various sizes centered at the same estimate (large black dots).
d'
d''
So far so good.
Now suppose that the location of the estimate is slightly changed, by moving it a bit to the left. Here is the new picture:
d'
d''
In this case, the change has no impact on the robustness of decision d'. On the other hand, decision d'' now has zero robustness: d'' does not satisfy the performance requirement at the new estimate.
The failing of Info-Gap's decision-making model is vividly illustrated by the following tale of the Treasure Hunt:
Treasure Hunt
The island represents the complete region of uncertainty under consideration (the region where the treasure is located).
The tiny black dot represents the estimate of the parameter of interest (estimate of the location of the treasure).
The large white circle represents the region of uncertainty pertaining to info-gap's robustness analysis.
The small white square represents the true (unknown) value of the parameter of interest (true location of the treasure).
So, basing our search plan on Info-Gap Decision Theory, we may zero in on the neighborhood of downtown Melbourne, while for all we know, the true location of the treasure may well be in the Middle of the Simpson desert, or perhaps just north of Brisbane.
Perhaps.
FAQ-18:What is the exact relationship between Info-Gap's robust model and Wald's Maximin model?
Answer-18: Info-Gap's robustness model is a simple instance of Wald's famous Maximin model (1945).
That is, Info-Gap's robustness model is a specific case of Wald's famous Maximin model that can be obtained in a straightforward manner by instantiating the elements of the general Maximin model according to a simple recipe.
Recall that the classic format of Wald's maximin model is as follows:
z* :=
max
min
f(x,s)
x∈X
s∈S(x)
where X denotes the decision space, S(x) denotes the set of states associated with decision x, and f(x,s) denotes the reward generated by the decision-state pair (x,s).
The equivalent Mathematical Programming format is as follows:
z* =
max
{v: v ≤ f(x,s), ∀s∈S(x)}
x∈X
v∈ℜ
where ℜ denotes the real line.
All we need to do to show that Info-Gap's robustness model is an instance of Wald's Maximin model is to instantiate the set X, the collection of sets S(x), x∈X and the function f=f(x,d) in such a way that the resulting Maximin model will be equivalent to Info-Gap's robustness model.
So consider the instance of Wald's Maximin model specified as follows in terms of the elements of Info-Gap's robustness model:
where ◊ denotes the binary operation on the real line such that a ◊ b = 1 iff a≥b and a ◊ b = 0 otherwise.
For this set-up we obtain the following instance of the Mathematical Programming representation of Wald's maximin model
z* =
max
{v: v ≤ f(x,s), ∀s∈S(x)}
x∈X
v∈ℜ
=
max
{v: v ≤ α·(r(d,u)◊r*), ∀u∈U(α,û)}
d∈D,α≥0
v∈ℜ
=
max
{α: α ≤ α·(r(d,u)◊r*), ∀u∈U(α,û)}
d∈D,α≥0
=
max
{α: r(d,u) ≥ r*, ∀u∈U(α,û)}
d∈D,α≥0
=
max
max {α: r(d,u) ≥ r*, ∀u∈U(α,û)}
d∈D
So, ... as expected, the above set-up indeed derives an Info-Gap robustness model from the Mathematical Programming formal of the Maximin model.
Thus, written in the classic Maximin format, Info-Gap's decision-making model looks like this:
α(û) :=
max
min
α·(r(d,u)◊r*)
d∈D
u∈U(α,û)
α≥0
Remark:
Observe that not only is Info-Gap's decision-making model a Maximin model, its robustness model is also a Maximin model. That is,
Maximin Theorem (Sniedovich 2007a, 2008a, 2008b, 2008c), WIKIPEDIA
α(d,û):= max {α: r(d,u) ≤ r*, ∀u∈U(α,û)} ≡
max
min
α·(r(d,u)◊r*)
α≥0
u∈U(α,û)
If you are familiar with stability theory and/or control theory, you must have noticed that Info-Gap's robustness measure in fact yields nothing more and nothing less than what is known universally as the stability radius of the system under consideration.
So, here is my short sermon on this topic for the benefit of Info-Gap scholars.
The concept "radius of stability" is perhaps the most well known measure of local stability/robustness. It was formulated so as to provide a means for determining stability against small perturbations in a given nominal value. Since this is precisely what Info-Gap robustness is all about, it is surprising that there is no mention of this concept in the official Info-Gap literature.
So, here is a very abstract, non-technical description of this important notion.
Consider a system that can be in either one of two states: a stable state or an unstable state, depending on the value of some parameter p. We also say that p is stable if the state associated with it is stable and that p is unstable if the state associated with it is unstable. Let P denote the set of all possible values of p, and let the "stable/unstabe" partition of P be:
S = set of stable values of p. We call it the region of stability of P.
I = set of unstable value of p. We call it the region of instability of P.
Now, assume that our objective is to determine the stability of the system with respect to small perturbations in a given nominal value of p, call it p'. In this case, the question that we would ask ourselves would be as follows::
How far can we move away from the nominal point p' (under the worst-case scenario) without leaving the region of stability S?
The "worst-case scenario" clause determines the "direction" of the perturbations in the value of p': we move away from p' in the worst direction. Note that the worst direction depends on the distance from p'. The following picture illustrates the simple concept behind this fundamental question.
Consider the largest circle centered at p' in this picture. Since some points in the circle are unstable, and since under the worst-case scenario the deviation proceeds from p' to points on the boundary of the circle, it follows that, at some point, the deviation will exit the region of stability. This means then that the largest "safe" deviation from p' under the worst-case scenario is equal to the radius of the circle centered at p' that is nearest to the boundary of the region of stability. And this is equivalent to saying that, under the worst-case scenario, any circle that is contained in the region of stability S is "safe".
So generalizing this idea from "circles" to high-dimensional "balls", we obtain:
The radius of stability of the system represented by (P,S,I) with respect to the nominal value p' is the radius of the largest "ball" centered at p' that is contained in the stability region S.
The following picture illustrates the clear equivalence of "Info-Gap robustness" and "stability radius":
In short, for all the spin and rhetoric, hailing Info-Gap's local measure of robustness as new and radically different, the fact of the matter is that this measure is none other than the "old warhorse" known universally as stability radius.
And as pointed out above, what is lamentable about this state-of-affairs is not only the fact that Info-Gap scholars fail to see (or ignore) this equivalence, but that those who should know better, continue to promote this theory from the pages of professional journals. See my discussion on Info-Gap Economics.
FAQ-19:What is the significance of the proof that Info-Gap's decision-making model is a Maximin model in disguise?
Answer-19: The proof showing that Info-Gap's robustness model is a simple Maximin model (in disguise) has the following implications for Info-Gap decision theory:
It refutes Ben-Haim's persistent claims that Info-Gap's robustness model is not a Maximin model.
It gives the lie to the contention that Info gap's robustness model offers a new approach for modeling uncertainty that is radically different from all current theories for decision-making under uncertainty.
It provides some important clues for a better understanding of the fundamental flaws in Info-Gap decision theory.
It shows what Info-Gap's decision theory really is, thus demonstrating its true place in Decision Theory.
FAQ-20:What are the errors in Ben-Haim's argument that Info-Gap's robust model is not a Maximin model?
Answer-20: Ben-Haim keeps changing his mistaken explanation as to why Info-Gap's robustness model is not a Maximin model. So, you may have encountered various versions of the explanation.
Be that as it may, the error in the various explanations is due to a profound misconception as to what a Maximin model is.
Maximin models are based on the idea that decisions are evaluated on the basis of their worst-case performance with respect to the unknown state of Nature. So translating this into the Info-Gap context, the question that needs to be asked is: what is the meaning of "worst case" in the framework of Info-Gap's robustness model?
Since Info-Gap's robustness model seeks robustness with regard to a constraint, namely a performance requirement such as r(d,u) ≥ r*, ∀u∈U(α,û), the notion worst case must also be defined with respect this constraint.
Yet, for some odd reason Ben-Haim considers a "worst case" to be with regard to the (smallest) value of r(d,u), and not with regard to the constraint r(d,u) ≥ r*. This of course is a fundamental error as to how worst case comes into play in Maximin modeling and hence how it would apply in the framework of Info-Gap decision theory.
Note that the worst-case scenario with regard to a constraint means that the constraint is not satisfied. Thus, insofar as constraints are concerned, there are only two mutually exclusive "events" to consider:
The constraint is satisfied.
The constraint is not satisfied.
Let us call these events "Yes" and "No" respectively.
This means that in the case of constraints, and therefore in the case of Info-Gap decision theory, there always is a worst-case scenario:
If the constraint is satisfied at every point in the region of uncertainty under consideration then the worst case with respect to this region is "Yes".
If the constraint is violated at one point or more in the region of uncertainty under consideration then the worst case with respect to this region is "No".
The erroneous argument that Ben-Haim often puts forth to support his claim that Info-Gap's robustness model is not a Maximin model runs as follows: the size (α) of the regions of uncertainty deployed by Info-Gap's decision model is unbounded. Therefore, there can be no worst case for α because for each value of α there always is a larger (even worse) value. For instance, consider this:
We note that robust reliability is emphatically not a worst-case analysis. In classical worst-case min-max analysis the designer minimizes the impact of the maximally damaging case. But an info-gap model of uncertainty is an unbounded family of nested sets: U(α,û), for all α≥0. Consequently, there is no worst case: any adverse occurrence is less damaging than some other more extreme event occurring at a larger value of α. What Eq. (1) expresses is the greatest level of uncertainty consistent with no-failure. When the designer chooses q to maximize α(q,rc) he is maximizing his immunity to an unbounded ambient uncertainty. The closest this comes to "min-maxing" is that the design is chosen so that "bad" events (causing reward R less than rc) occur as "far away" as possible (beyond a maximized value of α).
Ben-Haim (1999, pp. 271-2 )
An almost identical argument appears in Ben-Haim (2001, p. 85; 2006, p. 101).
The blunder in this argument is obvious. In the framework of Info-Gap's robustness model the factor deciding how good/bad a decision is at a given point u in the uncertainty region is not α but the performance constraint r(d,u) ≥ r*. Thus, as explained above, in this framework there are only two cases: a "Yes" case and a "No" case.
As α increases and the first "No" event is encountered for some u in U(α,û') as a result of the constraint being violated at u, no further increase in the value of α above α' can generate anything that is worse than "No". The "No" is the worst that can happen.
Remark:
This blunder could have been amusing had it not been so serious. The point is this. The object that Ben-Haim claims is unbounded above, namely α, is the very same object that Info-Gap's robustness model sets out to ... maximize!
α(d,û):= max {α≥0: r(d,u) ≤ r*, ∀u∈U(α,û)} , d ∈ D
What kind of theory sets itself the goal of maximizing a variable that it takes to be unbounded above?!
Clearly this does not make much sense.
The resolution of this blunder is rather simple. Insofar as modeling the uncertainty in Info-Gap's uncertainty model is concerned, the value of α is unbounded, and can be so till kingdom come! But the point is that to determine robustness, the value of α is implicitly bounded by the performance constraint r(d,u) ≥ r*,∀u∈U(α,û).
So α is bounded whenever robustness is bounded and it does have a worst case after all.
Another mistaken argument put forward by Ben-Haim to explain why Info-Gap's robustness model is not a Maximin model is based on an ill-conceived comparison between the Maximin model and Info Gap's decision-making model, where the alleged difference between them is put down to the "status" of α.
For some odd reason Ben-Haim holds that the value of α must be fixed in the formulation of a Maximin model. So, comparing the Maximin model where the value of α is allegedly fixed (known in advance) to Info-Gap's robustness model where the largest admissible value of α associated with a given decision is unknown in advance, Ben-Haim concludes the following: As there is no guarantee that the value assigned to α in the formulation of the Maximin model will be equal to that obtained by Info-Gap's robustness model, it follows that the two models are dissimilar.
The error giving rise to this ill-conceived comparison is of course in the presupposition that the value of α must be fixed in advance in the framework of a Maximin model. Not only is this contention grossly mistaken, but as we have seen in FAQ-18, it is a straightforward affair to incorporate α as a component of the decision variable of a Maximin model.
This error is also intriguing because it shows that it does not even occur to Ben-Haim to explain why it is OK to treat α as a control (decision) variable, rather than a constant, in the framework of Info-Gap's robustness model, whereas this is not OK in the framework of the Maximin model.
More on Ben-Haim's mistaken arguments concerning the relationship between Info-Gap's robustness model and Wald's Maximin model can be found in Sniedovich (2008b) and in the WIKIPEDIA article on Info-Gap.
PostScript:
For the benefit of mathematically oriented readers, here is a summary of the error in Ben-Haim's treatment of the relationship between Info-Gap's decision-making model and Wald's Maximin model:
Info-Gap's decision-making model
α(û) =
max
max {α≥0: r(d,u) ≥ r*, ∀u∈U(α,û)}
d∈D
Ben-Haim's Wrong Maximin model
Correct Maximin model
α(û;α'):=
max
min
r(d,u)
d∈D
u∈U(α',û)
α(û):=
max
min
α·(r(d,u) ◊ r*)
d∈D
u∈U(α,û)
α≥0
Note: α' is a prespecified positive number.
Note: a◊b =1 iff a≥b; a◊b =0 otherwise.
Obviously, there is a value of α' such that the optimal decision generated by Ben-Haim's model for this value is optimal with respect to the Info-Gap model. The difficulty is that this magic value is not known in advance.
In contrast, the correct Maximin model generates this magic value of α, namely α'=α(û), as an integral part of the maximization operation.
And to better appreciate how misguided Ben-Haim's Maximin model is, note that if the performance constraint of Info-Gap's robustness model is of the form r(d,u) ≤r*, then Ben-Haim's model would be as follows:
α(û;α'):=
min
max
r(d,u)
d∈D
u∈U(α',û)
That is, it would be a Minimax, rather than a Maximin, model.
Answer-21: In the framework of Info-Gap decision theory, the opportuneness of a decision d∈D is defined as follows (assuming that the larger r(d,u) is the better):
β(d,û):= min {α≥0: r(d,u) ≥ r*, for some u∈U(α,û)} , d∈D
In words, the opportuneness of a decision d is the size of the smallest region of uncertainty such that the performance requirement is satisfied at least at one point in that region.
Apart from offering a new coinage -- which might give the impression that the term "Opportuneness" introduces a new idea into Decision Theory -- the fact is that the idea conveyed by this term has been part of classical decision theory at least since the 1950s. It is called "Optimism Criterion" and it is in fact applied in Hurwicz' famous "Optimism-Pessimism Criterion" (Resnik 1987, French, 1988).
Formally, this concept can be expressed by a Minimin model. That is, it can be easily shown (eg. see WIKIPEDIA) that
β(d,û):=
min
{α≥0: r(d,u) ≥ r*, for some u∈U(α,û)}
=
min
min
α·(r(d,u) ◊ r*)
α≥0
u∈U(α,û)
where ◊ denotes the binary operation on the real line such that a ◊ b = 1 iff a ≥ b and a ◊ b = ∞ otherwise.
FAQ-23:What is the role and place of Info-Gap decision theory in Robust Optimization?
Answer-23: Since Info-Gap's robustness model is a Maximin model, the kinds of problems that Info-Gap decision theory in effect handles are of course robust optimization problems. This means that Info-Gap should be seen as belonging in the wider context of Robust Optimization and, that its performance should be judged relative to other robust optimization methods.
However, as brought out by this discussion, it is precisely in this capacity that Info-Gap fails so dismally. This failure is of course due to Info-Gap's robustness model prescribing a local robustness analysis .
Indeed, the methodology put forward by Info-Gap bestows on it the dubious distinction of being the only method proposing that the search for robust decisions under conditions of severe uncertainty be confined to the neighborhood of a questionable estimate. All other methods proceed on the obvious assumption (without even theorizing about it) that, given the severe uncertainty, the true value of the parameter of interest is a big unknown. Hence, the main thrust in all other Robust Optimization methods is to come up with techniques capable of covering the complete region of uncertainty or in the very least approximate it.
In short, from the standpoint of Robust Optimization, Info-Gap decision theory is a robust optimization method whose robustness model is a local Maximin model so that robustness is defined as the "safe" area around the estimate. As such, this theory is unsuitable for the treatment of problems that are subject to severe uncertainty.
FAQ-24:How would you describe Info-Gap's robustness and opportuneness in the language of classical decision theory?
Answer-24: This is a very interesting and relevant question.
The point is that having -- wittingly or unwittingly -- divorced itself from classical decision theory, from the start Info-Gap decision theory has cut itself off from the fund of ideas and concepts, indeed the thinking that informs the discipline of decision-making in general and decision-making under severe uncertainty in particular. Worse, it has cut itself off from the mathematical idiom used in this discipline. The tendency in Info-Gap has thus been to reinvent wheels. This means that the mathematical idiom that it has been using to express its main theses is often awkward, hence not immediately recognizable for what it really is.
So, this is how I would explain to my students the workings of Info-Gap's robustness model, and opportuneness model:
Robustness Model:
DM
Nature
α(d,û):= max {α: r(d,u) ≥ r*, ∀u∈U(α,û)} =
max
min
α·(r(d,u)◊r*)
α≥0
u∈U(α,û)
Note: a ◊ b = 1 iff a ≥ r* ; a ◊ b = 0 otherwise.
From the viewpoint of classical Decision Theory, Info-Gap's robustness model is a game between a decision maker and Nature. The decision maker plays first and based on his decision Nature determines her state. Nature is an adversary: She plays against the decision maker.
The decision maker decides on the size (α) of the largest safe region of uncertainty around the estimate. Given the decision maker's choice of an α, Nature will select the worst u in U(α,û) relative to the performance requirement. Namely, Nature will strive to find a u in U(α.û) that violates this requirement.
The reward to the decision-maker is either α -- if Nature cannot violate the performance requirement on U(α,û) -- or 0 if Nature finds a u in U(α,û) that violates this requirement.
Opportuneness Model:
DM
Nature
α(d,û):= min {α: r(d,u) ≥ r*, for some u∈U(α,û)} =
min
min
α·(r(d,u)◊r*)
α≥0
u∈U(α,û)
Note: a ◊ b = 1 iff a ≥ r* ; a ◊ b = ∞ otherwise.
In this case, Nature cooperates with the decision maker. So aiming for the best, the decision maker tries to find the smallest value of α such that the performance requirement is satisfied at some point in U(α,û). In response to a choice of α by the decision maker, Nature will try to find a point in U(α,û) that satisfies the performance requirement.
The reward to the decision maker is equal to α if the state u selected by Nature satisfies the requirement, otherwise it is equal to ∞ (penalty to deter the decision maker from selecting a larger than necessary α, and Nature for failing to select the best u in the given region of uncertainty selected by the decision maker).
I hasten to add that as pointed out by some experts, the Minimin or Maximax models -- on their own - cannot seriously be considered as frameworks for decision-making under severe uncertainty because these models' underlying approach to uncertainty is far too optimistic, meaning that they would be extremely difficult to justify. For instance consider what French (1988, p.37), who does not even list this model as a contender, has to say:
" ... It is, perhaps, a telling argument against Wald's criterion that, although there are many advocates of the approach, there are few, if any, of the maximax return criterion. Why is it more rational to be pessimistic than optimistic? An old proverb may tell us that `it is better to be safe than sorry', and it is true that Wald's criterion is as cautious as possible; but one must remember also that `nothing ventured, nothing gained'. ... ''
Another example is Resnik (1987). Introducing Hurwicz's Optimism-Pessimism Rule, Resnik (1987, p. 32) states the following:
"... The maximin rule reflects the thinking of a conservative pessimist. An unbridled optimist, by contrast, would tell us to maximize maximums. He would assume that no matter which act we chose the best outcome compatible with it will eventuate, and accordingly, he would urge us to aim for the best of the best . This thinking would give rise to what one would call the maximax rule. But that rule surely would have few adherents.
...''
FAQ-25:How is it that no references can be found in the Info-Gap literature to the thriving field of "Robust Optimization"?
Answer-25: Excellent question! It alludes to a fact that speaks volumes about Info-gap!
It is indeed totally incomprehensible how two editions of a book (Ben-Haim, 2001, 2006), devoted entirely to robust decision-making (in the face of Severe Uncertainty), propounding a methodology that in effect amounts to a Maximin model (albeit in disguise) can manage to avoid all reference to the field of "Robust Optimization".
This omission is particularly inexcusable given that one of the main theses in these books (indeed in most of the Info-Gap literature) is that Info-Gap decision theory is a new theory that is radically different from all current theories for decision under uncertainty. So, the point here is that not only is this thesis given no substantiation whatsoever, no attempt is made to investigate the relationship between the (purported) "radically different" Info-Gap robustness model and other, conventional, robust optimization models.
So, all that is left to do here is to remind Info-Gap proponents of the work done in the area of Robust Optimization, in particular by Ben-Tal and Nemirovski (eg. 1998, 1999, 2002) and Ben-Tal et al (2006).
FAQ-26:How exactly does Info-Gap "deal" with the severity of the uncertainty?
Answer-26: By ignoring it!
The Info-Gap literature goes out of its way to point out that Info-Gap is concerned with the most exacting uncertainty imaginable. For instance, consider this:
Making Responsible Decisions (When it Seems that You Can't)
Engineering Design and Strategic Planning Under Severe Uncertainty
What happens when the uncertainties facing a decision maker are so severe that the assumptions in conventional methods based on probabilistic decision analysis are untenable? Jim Hall and Yakov Ben-Haim describe how the challenges of really severe uncertainties in domains as diverse as climate change, protection against terrorism and financial markets are stimulating the development of quantified theories of robust decision making.
The question is then: what secret formula does Info-Gap bring to bear to accomplish this feat?
And the answer -- peculiar though it is -- is that Info-Gap's secret formula (as indicated in FAQ-15) is to ignore the severity of the uncertainty altogether.
This is done by transforming the difficult problem posed by the severity of the uncertainty into a much simpler, naive problem that addresses the following question:
What is the largest region of uncertainty around the estimate that satisfies the performance requirement?
In this context a region of uncertainty is said to satisfy the performance requirement if every point in this region satisfies this performance requirement. And because Info-Gap's regions of uncertainty are nested, this question is equivalent to the following question:
What is the largest value of α such that the performance requirement is satisfied over U(α,û)?
Now, suppose that the largest value of a "safe" α is equal to say α*=100. In turn, this means that in evaluating the largest safe region of uncertainty around û we take no notice whatsoever of what happens outside this region, or more precisely outside the region, say U(100.001,û). The point of course, is that it is possible that the entire region outside U(100.001,û) -- which I call Info-Gap's No Man's Land -- is safe, but this is all but ignored by Info-Gap's robustness analysis.
Here is a schematic representation of the situation:
û
<-------- U --- Complete Region of Uncertainty --- U -------->
The black area represents the complete region of uncertainty and the white dot represents the estimate of the parameter of interest.
And here is a schematic representation of the result generated by Info-Gap's robustness analysis for decision d, where the red area represents the largest safe region around the estimate.
No Man's Land
No Man's Land
U(α(d,û),û)
Safe
In sum, as amply brought out by this simple illustration, Info-Gap's prescription for tackling severe uncertainty is simply to ignore the severity of the uncertainty.
FAQ-27: Why do you make it a rule to assume that the "safe" area around the estimate is minutely small?
Answer-27: This brings to light the consequences of the thinking underlying Info-gap's mode of operation!
I make it a rule to assume that this is the case because any meaningful discussion on Info-Gap decision theory as a methodology for decision making under severe uncertainty must consider this case as the "text book" case, or even the "real test case".
There are a number of compelling reasons for this:
According to the Father of Info-Gap (eg. Ben-Haim 2006, p. 210; emphasis is mine):
" ... Most of the commonly encountered info-gap models are unbounded ..."
So in most commonly encountered cases any bounded safe region around the estimate would be infinitesimally small relative to the total (unbounded) region of uncertainty.
According to Hall and Ben-Haim (2007), one of the important distinguishing features of Info-Gap decision theory, compared with other methods such as Imprecise Probability, is that Info-Gap allows the boundaries of the sets of possible values of the parameter of interest to be unknown, hence unbounded.
From a methodological point of view, there is no reason to assume a priori that the safe area around the estimate is relatively large, so to "test" the methodology we must consider cases where this region is relatively small.
Cases where the safe region around the estimate is very large are, methodologically, of little interest in this context.
As far as I am concerned, the true importance of this assumption is that it brings into sharp focus the local nature of Info-Gap's robustness analysis and the absurd consequences arising from this analysis under conditions of severe uncertainty.
FAQ-28:What question does Info-Gap's robustness model actually address??
Answer-28: Excellent question!
Before I proceed to answer this question, I need to make clear how this issue arises in the first place. In the Info-Gap literature, much is made of the fact that for disciplines confronted with the need to provide solutions for pressing real-world decision problems (eg. conservation biology), the great merit of Info-Gap is that its robustness model allows addressing, indeed answering, questions such as
Ben-Haim (2006, p. 285):
How wrong can the current estimate of future returns be, without jeopardizing the attainment of a specified level of utility?
Halpern et al (2006, p. 2):
How wrong can one be and still get an acceptable result?
Ben-Haim (2007, p. 2):
how wrong can our best guess be, and the contemplated decision still yields adequate results?
McCarthy and Lindenmayer (2007, p. 554):
How wrong can one be and still get an acceptable result?
Burgman (2007):
How wrong could this model be before I should change my decision?
Fox et al (2007, p. 192): How wrong can a model and its parameters be without jeopardising the quality of decisions made on the basis of this model?
Burgman (2008):
How wrong can this model be, without jeopardizing an acceptable level of performance?
The truth of course is -- as amply demonstrated by the discussion thus far -- that contrary to any such claims, Info-Gap's robustness model neither addresses, much less is it able to answer, questions such as these.
The reason for this is very simple: given that Info-gap's robustness model operates under conditions of severe uncertainty, the true value of the parameter of interest is UNKNOWN. Hence, from the word go, there is no criterion at hand to judge how wrong or how correct a model or data are. That is, there is no way of knowing how wrong a given u∈U is because we do not know the value of u* -- the true value of u.
Indeed, all that Info-Gap users would be justified to assume is that, given the severe uncertainty, the model or data they begin with are at best questionable.
So the issue is then what question does Info-gap's robustness model in fact address?
And the answer to this is also very simple. By definition, Info-Gap's robustness model (see FAQ-11) seeks to answer the following question:
What is the largest value of α such that decision d satisfies the performance requirement at all the points in U(α,û)?
If we agree to use the term "safe" to indicate that the performance requirement is satisfied at all the points in U(α,û), then we can rephrase this question as follows:
What is the largest value of α such that decision d is "safe" on U(α,û)?
To state it informally,
What is the size of the largest "safe" region of uncertainty around the estimate?
And this has got nothing to do with how wrong or right your estimate is. Indeed, you can ask the same question about any given point u in U, not necessarily the estimate, and you can ask this question even if there is no uncertainty at all!
FAQ-29:How do you explain the emergence of Info-Gap as a (presumably) novel methodology for decision-making under of severe uncertainty?
Answer-29: To work out an answer to this question we need to trace out Info-Gap's evolution from its beginnings in "Robust Reliability in the Mechanical Sciences" (Ben-Haim's 1996) to its present state in (Ben-Haim 2001, 2006).
Reading (Ben-Haim 1996) it is clear that the generic robustness model outlined in this book is not recognized for what it is, namely a Maximin model. This of course is puzzling because all the telltale signs attesting to this model being a Maximin model are everywhere in this book.
To begin with, the explicit reference to Witsenhausen's (1968) paper entitled "A minimax control problem for sampled linear systems" in Ben-Haim (1996, p. viii) should have rung the Maximin alarm bell.
More importantly, the description of the "Vehicle vibration on rough terrain" problem (Ben-Haim 1996, p. 9) should have rung the same bell (the emphasis is mine):
" ... Statistical models have been employed for representing the variation of uncertain terrain[74]. However, verifications of these models is time consuming and expensive. Alternatively, global features of the surface which are comparatively easily measured, such as maximum roughness or slope variation or other features can be used as to define sets of possible substrates. These sets are convex models of the substrate uncertainty.The design decisions are then made so as to assure that the worst ride (e.g. maximum instaneous acceleration) induced by any allowed substrate is acceptable [20, 21] ... "
The inevitable conclusion is then that later claims (Ben-Haim 2001, 2006) proclaiming Info-Gap a new and radically different methodology, go back to this initial failure to recognize (Ben-Haim 1996) that the robustness model developed in this book is in fact a Maximin model in disguise.
This initial error was then further compounded when the methodology developed in Ben-Haim (1996) was later reintroduced in Ben-Haim (2001, 2006) as a novel approach to decision making under Severe Uncertainty without any adjustment in the model to empower it meeting the exacting requirements of severe uncertainty.
In greater detail:
It is clear that in Ben-Haim (1996) the uncertainty is not taken to be severe. To the contrary, one's impression is that the uncertainty in question is very mild. And what is more, no reference whatsoever is made to Knightian uncertainty!!
Here is the description of the "Buckling of thin-walled shells" problem (Ben-Haim, 1996, p. 9; emphasis is mine):
"... For example, a sheet of paper stood on end buckles under slight pressure, while if rolled into a cylinder and taped it can withstand an axial loading of considerable weight. However, small geometrical imperfections in the shape of the shell can drastically reduce the maximum load which the shell can carry. ..."
and on p. 53:
"... Consider the cross section of the shell before loading as in fig.3.5. The actual shape deviates from the nominal circular shape due to geometrical imperfections which are of course greatly exaggerated in this figure. ..."
Clearly, the "nominal shape" here is not a poor estimate: it is the exact nominal shape.
By the same token, although the models do not impose an upper bound on the size of the region of uncertainty (α), this feature is barely mentioned, let alone discussed, in Ben-Haim (1996).
Yet, precisely the same model, prescribing precisely the same treatment of uncertainty, is transferred lock stock and barrel to the two more recent Info-Gap books (Ben-Haim, 2001, 2006) whose concern is with decision under severe uncertainty.
Thus, inexplicably, the selfsame methodology suddenly becomes a methodology for dealing with severe, in fact Knightian, uncertainty.
The sole difference between the methodology outlined in (Ben-Haim 1996) and Info-Gap of (Ben-Haim 2001 2006) is in the accompanying rhetoric and jargon.
Info-gap of Ben-Haim (2001 2006) bursts with effusive rhetoric about the horrors of Knightian Uncertainty that it is purportedly designed to tackle. Yet, for all this rhetoric and new jargon it is ill-equipped to meet this challenge.
All that it is capable of doing is that which it was set up to do in Ben-Haim (1996), namely determine robustness of decisions in the neighborhood of a given nominal value of the parameter of interest. In fact, some of the robustness models in Ben-Haim (1996) do not even require a nominal value, eg. the modally-truncated model (Ben-Haim, 1996, pp. 160-161).
But this, as we have seen, does not even come close to tackling Severe Uncertainty.
FAQ-30: Are there any indications in the Info-Gap literature attesting to an awareness of the GIGO principle?
Answer-30: Indeed there are!
For instance, consider the following (Ben-Haim 1996, p. 206):
'... Finally, a reliability theory is only as good as the information upon which it rests. A reliability theory should exploit all relevant verified information, but should treat speculative information and "reasonable assumptions" with caution. ...'
Yet, Info-Gap (Ben-Haim, 2001, 2006) propounds the following paradigm :
FAQ-31: Isn't some of your criticism of Info-Gap, notably your dubbing it a "voodoo decision theory" unfair indeed hyperbolic?
Answer-31: Definitely not!
My criticism of Info-Gap decision theory is totally justified as it is based on a careful formal analysis of its uncertainty, robustness, and decision-making models.
I have formally proved that
Info-Gap's robustness model is a Maximin model.
Info-Gap's robustness model fails to tackle severe uncertainty.
I have also demonstrated by means of a cogent argument that the contention that Info-Gap's robustness model generates reliable results is in violation of the GIGO principle.
A religion practiced throughout Caribbean countries, especially Haiti, that is a combination of Roman Catholic rituals and animistic beliefs of Dahomean enslaved laborers, involving magic communication with ancestors.
Somebody who practices voodoo.
A charm, spell, or fetish regarded by those who practice voodoo as having magical powers.
A belief, theory, or method that lacks sufficient evidence or proof.
My usage of the term voodoo decision theory is in line with the meaning given in the fourth entry.
So roughly, in this discussion voodoo decision-making is taken to be a decision-making process that is guided and/or inspired by a voodoo decision theory, that is a theory that lacks sufficient evidence or proof and/or is based on utterly unrealistic and/or contradictory assumptions, spurious correlations, and so on.
This reading is also in line with the widely used terms Voodoo Economics and Voodoo Science.
I should point out, though, that the term "Voodoo Decision Theory" is not my coinage (what a pity!):
The behavior of Kropotkin's cooperators is something like that of decision makers using the Jeffrey expected utility model in the Max and Moritz situation. Are ground squirrels and vampires using voodoo decision theory?
Brian Skyrms (1996, p. 51) Evolution of the Social Contract
Cambridge University Press.
The best example I have of a voodoo decision theory is Info-Gap Decision Theory. The picture is this:
wild guess ---->
Info-Gap Robustness Model
----> robust decision
I am currently working on a short book on this topic, tentatively entitled: "The Rise and Rise of Voodoo Decision Theories". Let me know if you have other examples.
FAQ-33:What is the meaning of the term "information-gap" in the framework of Info-Gap Decision Theory?
Answer-33: In the framework of Info-Gap decision theory, the term "information-gap" denotes the disparity (gap) between the estimate û and the true value of the parameter u.
In plain language, it is the (unknown) "error" -- due to uncertainty -- in our estimate û.
Of course, under severe uncertainty this error can be substantial.
The flaw in Info-Gap's robustness analysis is that it focuses exclusively on the neighborhood of the estimate. The picture is this:
Decision-making under severe uncertainty is all about the gap between the estimate û and the unknown true value u*, whereas Info-Gap decision theory is all about the gap between the estimate û and its neighbors, eg. u in the picture.
FAQ-34:What is the difference between "robust-optimal" and "robust-satisficing" decisions in the framework of Info-Gap decision theory?
Answer-34: Insignificant!
The difference is basically in the jargon. Thus, in the first edition of the book (Ben-Haim 2001) the term "robust optimal" designates the optimal decision selected by Info-Gap's decision-making model. For example, on p. 76 the optimal investment generated by Info-Gap's decision-making model for the portfolio investment problem studied there is dubbed "Robust-Optimal Investment".
The same investment is dubbed "Robust-satisficing Investment" in the second edition (Ben-Haim 2006, p. 71). Interestingly, though, despite this deliberate shift in the jargon, some remnants of "Robust-Optimal" from the first edition can still be found in the second edition of the book, eg. Bem-Haim (2006, p. 182).
Before I proceed to explain whence this shift in jargon, I need to point out that the term "Robust-satisficing" indicates robustness that is sought with respect to a "constraint" rather than an "objective function".
The shift from "Robust-Optimal" to "Robust-satisficing" is in concert with the big deal that Info-Gap makes about the difference between Optimizing and Satisficing, and the alleged inability of optimization to deal with problems where performance requirements must be taken into account. For instance, in Ben-Haim (2006, pp. 100-101) we read:
If "rationality" means choosing an action which maximizes the best estimate of the outcome, as is assumed in much economic theory, then info-gap robust-satisficing is not rational. However, in a competitive environment, survival dictates rationality. In section 11.4 we will show that, for a wide range of situations, the robust-satisfier is more likely to survive than the direct optimizer. If "rationality" means selecting reliable means for achieving essential goals, then info-gap robust-satisficing is extremely rational.
This is much ado about nothing.
To all those who are well-versed in Optimization Theory this kind of rhetoric is no more than a storm in a tea cup.
For, if you are at home in Optimization Theory, you would no doubt know that Constrained Optimization provides precisely the means (mathematical models) enabling the incorporation of "performance requirements" in the formulation of "standard" optimization problems.
Furthermore, you would also know that the thriving field of "Robust Optimization" has developed precisely to deals with situations where robustness is sought with respect to constraints.
For example, Mulvey et al (1995, p. 264) draws the following distinction:
A solution to an optimization model is defined as: solution robust if it remains "close" to optimal for all scenarios of the input data, and model robust if it remains "almost" feasible for all data scenarios.
And Cornuejols and Tütüncü (2006, p. 8) draw a similar distinction between constraint-robust and objective-robust solutions. The explanation is as follows (Cornuejols and Tütüncü 2006, p. 292):
" ... Recall from Chapter 1 that there are different definitions and interpretations of robustness; the resulting models and formulations differ accordingly. In particular, we can distinguish between constraint-robustness and objective-robustness. In the first case, data uncertainty puts the feasibility of potential solutions at risk. In the second, feasibility constraints are fixed and the uncertainty of the objective function affects the proximity of the generated solutions to optimality. ...''
But most of all, you would know that any "satisficing" problem can be easily formulated as an equivalent "optimizing" problem, so -- mathematically speaking -- the distinction between "optimizing" and "Satisficing" is a matter of style rather than substance.
FAQ-35:What is the significance of Info-Gap allowing its complete region of uncertainty to be unbounded?
Answer-35: Excellent question. It brings into sharp focus the sloppy thinking that informs Info-Gap.
The point is this:
The fact that Info-Gap's complete region of uncertainty is allowed to be unbounded is hailed in the Info-Gap literature as a major coup. This feature is treated as giving Info-Gap an advantage over other methods because, so the argument goes, other methods cannot cope with unbounded uncertainty spaces.
But, reading such statements one wonders whether Info-gap proponents have stopped to think through the implications of this presumed great attribute. For, had they done so they would have realized that in the case of Info-Gap, rather than being an advantage, an unbounded uncertainty space is in fact calamitous.
This of course is due to Info-gap's robustness analysis being confined to a single (questionable) estimate and its neighborhood. The consequences of a local robustness analysis being conducted in an unbounded uncertainty space are nothing short of absurd, as amply brought out by this picture:
No Man's Land
û
No Man's Land
U(α(d,û),û)
-∞ <-----------------
Complete region of uncertainty
-----------------> ∞
One need hardly point out that it is practically impossible to faithfully depict the full dimensions of this absurd as no picture would be able to show an infinitesimally small "safe" region, namely U(α(d,û),û), that would be visible to the naked eye.
So the combined effect of the unbounded region of uncertainty and the local robustness analysis is that Info-Gap's No Man's Land constitutes practically the entire region of uncertainty.
FAQ-36:How do Info-Gap's proponents justify the use of the theory in cases where the complete region of uncertainty is unbounded?
Answer-36: They don't. They become entangled in greater contradictions!
I recently pointed out to an Info-Gap expert the absurd in making a big deal about Info-Gap's unbounded region of uncertainty when all that Info-Gap in effect does is to conduct a local analysis around a single estimate.
The expert's reply: but we are interested only in what happens in the region around the estimate!!!!
This reply speaks volumes about the messy thinking that pervades this entire enterprise.
Clearly, Info-Gap users have not thought through the theory's various claims, much less have they attempted to fit them all into one coherent view. So, while reciting the standard Info-Gap rhetoric about severe uncertainty, some use it for the purpose of determining the robustness of decisions in the neighborhood of a given estimate without realizing that this is not what Info-Gap decision theory was designed for.
But most of all, this reply is symptomatic of the muddled treatment of "Severe Uncertainty" in the Info-Gap literature. The term, to be precise "Knightian Uncertainty, is bandied about with abandon and the dissertations describing these conditions are endless. But no serious thought is given to the techniques that are required to tackle the special demands of "Severe (Knightian) Uncertainty".
So, when it comes to technically tackling problems that are subject to these conditions, all that Info-gap has to offer is a Maximin type analysis in the vicinity of a (questionable) estimate, in fact a wild guess.
What a mess!
FAQ-37:Is the true value of u more likely to be in the neighborhood of the estimate û?
Answer-37: Very relevant question. It goes to the very heart of Info-Gap decision theory.
There is nothing in Info-Gap decision theory to suggest that the true value of the parameter of interest is more/less likely to be in any one particular neighborhood of the complete region of uncertainty. Thus, no explicit or implicit assumptions are made as to the likelihood of the true value of u being or not being near the estimate û.
Ben-Haim is crystal clear on this issue (empahsis is mine):
While uncertainty in the shell shapes is fundamental to this analysis, there is no likelihood information, either in the formulation of the convex model or in the concept of reliability
.........
........
However, unlike in a probabilistic analysis, r has no connotation of likelihood. We have no rigorous basis for evaluating how likely failure may be; we simply lack the information, and to make a judgement would be deceptive and could be dangerous. There may definitely be a likelihood of failure associated with any given radial tolerance. However, the available information does not allow one to assess this likelihood with any reasonable accuracy.
Ben-Haim (1994, p. 152)
and
Classical reliability theory is thus based on the mathematical theory of probability, and depends on knowledge of probability density functions of the uncertain quantities. However, in the present situation we cannot apply this quantification of reliability because our information is much too scanty to verify a probabilistic model. The info-gap model tells us how the unknown seismic loads cluster and expand with increasing uncertainty, but it tells us nothing about their likelihoods.
Ben-Haim (1999, p. 1108)
and
In any case, an info-gap model of uncertainty is less informative than an probabilistic model (so its use is motivated by severe uncertainty) since it entails no information about likelihood or frequency of occurrence of u-vectors.
Ben-Haim (2001a, p. 5)
and
In info-gap set models of uncertainty we concentrate on cluster-thinking rather than on recurrence or likelihood. Given a particular quantum of information, we ask: what is the cloud of possibilities consistent with this information? How does this cloud shrink, expand and shift as our information changes? What is the gap between what is known and what could be known. We have no recurrence information, and we can make no heuristic or lexical judgments of likelihood.
Ben-Haim (2006, p. 18)
One need hardly point out that this position is totally justified, as taking the opposite position would be tantamount to a flagrant violation of the meaning of Severe Uncertainty.
That is, holding that one's model is subject to Severe Uncertainty dictates that one proceed on the assumption that the location of the true value is unknown and hence, cannot be postulated to be in any one particular neighborhood.
So far so good.
And yet, despite it correctly making no assumptions as to the likely location of the true value, Info-Gap's mode of operation (definition of robustness and robustness analysis) flies in the face of this position.
The result is an untenable self-contradiction.
For, while admitting that the estimate is a wild guess, perhaps no more than a rumor, hence, by implication, that there is no reason to believe that the true value is likely to be in the neighborhood of the estimate; it nevertheless confines the robustness analysis to the neighborhood of this estimate.
This is precisely the reason for my labeling Info-Gap decision theory a voodoo decision theory.
Info-Gap cannot have it both ways:
If the uncertainty is severe so that the estimate is a wild guess, perhaps just a rumor, then there is no reason to believe that the true value of u is near the estimate. Thus, it makes no sense to conduct a robustness analysis only in the neighborhood of the estimate, as such an analysis cannot be counted on to yield meaningful results in the face of severe uncertainty.
If it can be safely assumed that the true value of u is likely to be in the neighborhood of the estimate, then clearly the situation under consideration is not that of severe uncertainty where the estimate is a wild guess that is likely to be substantially wrong.
It is astounding that this contradiction has gone unnoticed in the Info-Gap literature.
FAQ-38:Can Info-Gap's uncertainty model be cast as a simple "probabilistic" model?
Answer-38: Of course it can!
For all the endless talk in the Info-Gap literature about Info-Gap being a non-probabilistic theory, the fact is that Info-Gap's uncertainty model can easily be cast as a probabilistic model.
This interpretation is discussed in details in Sniedovich (2006a). For the purposes of this discussion it suffices to indicate the following.
All it takes to construct a probabilistic model for u is to assume that α is the realization of a random variable, call it α, having some probability density function. Furthermore, assume that for each value of α we associate a unique value of u, call it u(α), according to the following rule:
u(α):= worst element of U(α,û) as far as the performance requirement is concerned.
For example, if the performance requirement is r(d,u) ≥ r*, we can let u(α) be an element of U(α,û) that minimizes r(d,u) over U(α,û).
So conceptually, a realization of the true value of u is the result of a two-stage process:
Stage 1: a realization α of α is generated by the probability density function of α.
Stage 2: a realization of u given α is generated by the rule u(α).
This simple conceptual model provides a probabilistic interpretation of the robustness, α(d,û), of decision d:
α(d,û) =
max {α≥ 0: Pr[decision d satisfies the performance requirement at each u∈U(α,û) | α = α] = 1}
=
max {α≥ 0: Pr[r(d,u(α)) ≥ r* | α = α] = 1}
where Pr[e|c] denotes the conditional probability of event e given c.
Note that
Pr[r(d,u(α)) ≥ r* | α = α] = 1
, ∀ α≤α(d,û)
and
Pr[r(d,u(α)) ≥ r* | α = α] = 0
, ∀ α>α(d,û)
Thus, the probability that decision d will satisfy the performance constraint is
Pr[r(d,u(α)) ≥ r*] =
Pr[α ≤α(d,û)] = F[α(d,û)]
where F denotes the cumulative distribution function of α.
Remarks:
The choice of a pdf for α can be arbitrary, observing that the support of this pdf is the non-negative segment of the real line.
This choice does not affect the value of α(d,û).
This choice will, of course, affect the value of F[α(d,û)], but will not change the ranking of decisions based on these values if the cumulative distributions are strictly increasing.
Conceptually, the boundaries of the region of uncertainty can be viewed as the contour lines of the image of F on the complete uncertainty set U. Here is the picture:
Probabilistic Representation of Uncertainty
Info-Gap's Representation of Uncertainty
Pr[U(α,û)]
U(α,û)
Here P[U(α,û)] denotes the probability that the true value of u is the worst u in U(α,û) which is equal to the "volume" of the graph associated with the contour line of the region U(α,û). The graph of P[U(α,û)] should be appropriately scaled to insure that P[U]=1.
I should make it clear though that my aim is not to argue that Info-Gap is acceptable in this guise. My aim is to point out the obvious: Info-Gap's uncertainty model has a simple, intuitive probabilistic interpretation.
FAQ-39:What is Info-Gap's solution to the famous Two-Envelope Puzzle?
Answer-39: I have no idea! This is anybody's guess.
One of Info-Gap's main theses is that it fills in a gaping hole left by the shortcomings of Probability Theory. Its point is that an appeal to Laplace's Principle of Insufficient Reason (1825) not always enables the modeling of ignorance probabilistically. To substantiate this point it uses the two-envelope puzzle as an illustration (Ben-Haim 2006, p. 15).
It is important therefore to set the record straight.
The two-envelope puzzle can definitely be treated probabilistically with significant success. For a discussion on this issue see the article in WIKIPEDIA. Also see my paper on this topic (Sniedovich 2007b).
FAQ-40:Isn't it more accurate to view Info-Gap's decision-making model as a representation of an optimization problem rather than a satisficing problem?
Answer-40: In the absence of clear-cut definitions for "a satisficing problem" and "an optimization problem" the debate on "satisficing" vs "optimizing" is meaningless.
The Info-Gap literature makes a big fuss about the difference between "optimizing" and "satisficing" (see FAQ-34) its point being that "Satisficing" has an advantage over what it refers to as "direct" optimizing. The argument seems to be that "(direct) optimizing" concerns itself only with the maximization of profit or utility to the detriment of performance. The insinuation therefore seems to be that optimization is either unable to tackle problems requiring that performance be taken into account or worse, that it is negligent in this task.
Before we take up this matter it is vital to point out that there are no universally accepted definitions as to what constitutes a "strictly optimization problem" as opposed to a "strictly satisficing problem". So, unless Info-Gap provides clear cut definitions its entire argument remains meaningless.
Be that as it may, it is patently clear that Info-gap's decision-making model is an optimization model because it sets itself the task of maximizing robustness:
α(û) =
max
max {α: r(d,u) ≥ r*, ∀u∈U(α,û)}
d∈D
Now, the hullabaloo that the Info-Gap literature makes about this model is that it specifies a performance constraint, namely r(d,u)≥r*.
But anyone well-versed in Optimization Theory would immediately ask "so what of it?" Is it not a fact that most optimization problems are constrained so that the models representing them duly reflect this fact in the formulation?
In other words, what is the big deal about this particular model being a constrained optimization model?
But more than this. Why is it a-priori better, or more important, or whatever, to maximize robustness and constrain "whatever" to a pre-specified value; rather than maximize "whatever" and constrain the robustness to a pre-specified value, as in
ρ(û;α) :=
max
max {ρ: r(d,u) ≥ ρ, ∀u∈U(α,û)}
d∈D
where here α is a pre-specified positive number?
Note that this is a simple Maximin model, namely it can be rewritten as follows:
ρ(û;α) =
max
min
r(d,u)
d∈D
u∈U(α,û)
But most of all, Info-Gap's thesis that satisficing has an advantage over optimizing is, mathematically speaking, pointless, indeed counter-productive.
For, it can be easily shown that any satisficing problem of the form r(d,u) ≥ r*, ∀u∈U(α,�) can be re-formulated as an (equivalent) optimization problem such that any optimal solution to the latter is a feasible solution to the former and vice versa.
So, the real issue here is not whether we should optimize or satisfice. Rather the real issue is the following. Given a state-of-affairs that we formulate as a decision-making problem, we consider the tasks, aims, and goals that the problem presents us with so that the question we ask ourselves is: "what should be optimized and what should be satisfied?"
Remark:
Info-Gap's rhetoric on "satisficing" is astounding, especially when it is set off against its rhetoric on severe uncertainty. If you are unaware of what Info-Gap theory actually delivers, you may get the impression that we have here a major breakthrough in decision theory. For instance, consider these two paragraphs from the website of the Abramson Center for The Future of Health in Houston, Texas, USA:
" ... Info-gap is grounded in the Nobel prizewinning work of Herbert Simon, in which he identified the value of "satisficing" in improving the quality of a choice. It allows the user to operate in conditions of severe uncertainty -- such as is found in most clinical situations -- and to make decisions that not only match patients to the data that are relevant to their individual needs, but also are open to unexpected best outcomes, something that "playing the odds" cannot do.
Info-gap excels in conditions where the data are sparse, uncertain, and the result of failure is catastrophe. Standard clinical decision making strategies do not protect patients against errors in the clinical data. However, because info-gap is not probability-based, it provides a strong foundation for making decisions when there is not enough information--such as in the highly individualized world of the clinic. Info-gap also allows "real-time" decision making and rapid assessment, thus allowing for targeted answers without wasted time. ..."
" ... Non-invasive, Continuous Monitoring of Chronic Conditions, "Blue Box"
The blue box is a biomedical measurement device designed to capture customized personal data through non-invasive monitoring, perform web-based analysis and interpretation of the data, and provide guided intervention when individuals exceed their own normal range.
The initial project, now in development with our partners, Rice University, Technology for All, and Indus Instruments, is an affordable personalized chronic heart failure management system based upon wireless biomedical sensor networks. A medical anthropology study, directed by Jerome Crowder, PhD, will help ensure that the sensors integrate easily into people's lives. In 2008, Dr. Dacso, Ed Knightly, PhD, Lin Zhon, PhD, and Technology for All received a $1.5 million grant from the National Science Foundation for this project.
Blue Boxes are currently in initial testing for the management of diabetes and asthma. Prototypes are in development for monitoring of aortic aneurysm and hypertension.
Key components of the Blue Boxes are the concept of "personal normal" and the use of info-gap decision theory to interpret the patient's data in a meaningful way. A "personal normal" is a value that reflects the normal situation for that particular patient (which may not be the "norm" for any other person, or the one from the medical literature). However, deviation from this personalized normal, derived from the patient him or herself, over time, is a far better indicator of the patient's true condition than any "standardized" normal could ever be. Thus, the patient and his or her physician are able to tailor treatment to a degree that has never before been achieved. ..."
This applies to all the relevant expressions in the two books (Ben-Haim, 2001, 2006) and numerous articles in the Info-Gap literature.
FAQ-42:What is the relationship between Info-Gap's decision-making model and the robust optimization models of Ben-Tal and Nemirovski (1998, 2002)?
Answer-42: Methodologically speaking, Info-Gap's decision-making model is a special case of the robust optimization models formulated in Ben-Tal and Nemirovski (1998, 2002). This is not surprising because the models formulated in Ben-Tal and Nemirovski (1998, 2002) are essentially general Maximin models.
There is, however, one minor technical modeling issue that requires attending to. This is the seemingly simple structure of Ben-Tal and Nemirovski's (1998, 2002) uncertainty models. Whereas in Ben-Haim (2001, 2006) the uncertainty model consists of a family of nested regions U(α,û), α≥0, Ben-Tal and Nemirovski's (1998, 2002) models specify only a complete uncertainty space.
In other words, from the viewpoint of the classic Maximin formulation, the structure of the Maximin models in Ben-Tal and Nemirovski (1998, 2002) is essentially as follows:
p*:=
max
min
f(d,u)
d∈D
u∈U
observing that the objective function f may incorporate penalties representing constraints such as say h(d,u)≥0, ∀u∈U.
Often, it is more convenient to use the following Maximin format:
q*:=
max
min
g(d,u)
d∈D
u∈U(d)
where for each d∈D the set U(d) is a non-empty subset of U.
It should be noted, therefore, that, methodologically speaking, the difference between these two classic Maximin formats is basically stylistic.
In other words,
q*:=
max
min
g(d,u)
d∈D
u∈U(d)
≡
p*:=
max
min
f(d,u)
d∈D
u∈U
when f and g are related to each other as follows:
f(d,u)
=
g(d,u)
, if u∈U(d)
=
∞
, if u∉ U(d)
In short, in the case of Info-Gap we have
Info-Gap decision-making model
Classic Maximin formulation
α(û) :=
max
max
{α≥0: r(d,u)≥ r*, ∀u∈U(α,û)}
d∈D
≡
α(û) :=
max
min
h(d,α,u)
d∈D α≥0
u∈U
where the function h is defined as follows:
h(d,α,u)
:=
α
, if u∈U(α,û) and r(d,u) ≥ r*
:=
-∞
, if u∈U(α,û) and r(d,u) < r*
:=
∞
, if u∉U(α,û)
Note that in the framework of the Maximin model, the ∞ represents a penalty imposed on the min player to deter her from selecting a u outside U(α, û). In contrast, the -∞ represents a penalty imposed on the max player to deter him from selecting a decision d such that the performance requirement r(d,u) ≥ r* is violated at some point in U(α,û).
FAQ-43:Is it really so difficult to quantify severe uncertainty probabilistically?
Answer-43: This is indeed the question that needs to be asked first and foremost about Info-Gap. And to be sure, this is precisely the question that I am asked most often, mainly by statisticians. I might add that, this question was raised and debated at some length, during a question/answer period following a student's presentation, in our department, on November 28, 2008. Some of my colleagues go so far as to argue that in the context of a mathematical model, uncertainty should "always" be described by some sort of a probability model.
The point is that in those situations where Info-Gap is typically applied to, coming up with a rough probabilistic quantification of the parameter of interest is no more difficult a task than venturing a wild guess about it. The question of course is which is the better practice. Is it preferable (does it more accurately capture the situation?) to "wild-guess" a point estimate of the parameter of interest and conduct a robustness analysis around it -- as done by Info-Gap decision theory? Or, is it better to "wild-guess" a probabilistic model for this parameter?
It seems to me that the answer to this question is problem-oriented, namely it may vary from case to case. But most of all, it must be remembered that constructing a probabilistic model for the parameter of interest in itself does not guarantee robust decisions. You would still have to quantify robustness in the framework of the probabilistic model (see discussion FAQ-44).
Indeed, it is not uncommon to have "hard" constraints such as r(d,u) ≥r*,∀u∈U, even within a probabilistic model where u represents the realization of a random variable whose probability distribution function on U is given. The fact that such a constraint can be described probabilistically, eg. Pr[r(d,u)≥r*]=1, is beside the point.
Be that as it may, my criticism of Info-Gap decision theory is not directed at it being a non-probabilistic approach to the modeling and analysis of severe uncertainty. Not at all.
My criticism is directed at the manner in which it deals -- or rather fails to deal -- with the severity of the uncertainty.
FAQ-44:How do you "define" robustness probabilistically?
Answer-44: There are various ways to define robustness probabilistically.
For example, in the framework of the "satisficing" problems addressed by Info-Gap decision theory, we can define the robustness of decision d∈D as follows:
ρ(d) := Pr[r(d,u)≥r*|d]
where u denotes the random variable representing the true value of u, and Pr[e|d] denotes the conditional probability of event e given that the decision is d.
Note that this notation suggests that the probability distribution of u may depend on d -- which is not allowed by Info-Gap's generic uncertainty model.
There are, of course, other ways to do it. For instance, consider the following two cases:
ρ* := max {E[r(d,u)|d]: d∈D, Pr[r(d,u)≥r*|d] = 1}
ρº := max {P[r(d,u)≥rº|d]: d∈D, Pr[r(d,u)≥r*|d] = 1}
where E[a|b] denote the conditional expected value of a given b; and rº is some number greater than r*. Observe that under standard regularity conditions these two models are Maximin models in disguise.
It should be noted that seemingly similar formulations of robust optimization models may yield quite different results, some of which are counter intuitive (see for example Sniedovich (1979) -- yes, this date is correct!).
FAQ-45:Can you give an example of a "global" approach to robustness?
Answer-45: Sure. This will take us more than forty years back!
Perhaps the simplest most intuitive "global" approach to robustness is to "sample" the complete region of uncertainty and determine the number of sample points where a decision satisfies the performance requirement. The technical term used in the robust optimization literature to designate this technique is: scenario generation.
The following picture pits the local approach to robustness adopted by Info-Gap decision theory against the simple global approach to robustness based on scenario generation:
Local Approach to Robustness
a la Info-Gapdecision theory
Simple Global Approach to Robustness
via Scenario Generation
In this illustration the scenarios are generated by drawing a grid on the island. Each white node on the grid represents a value (scenario) of the parameter of interest. There are 59 scenarios in this example.
So all we have to do to evaluate the robustness of decision d with respect to the performance constraint r(d,u)≥r* is to count how many points on the grid satisfy this constraint:
N
ρ(d) :=
Σ
(r(d,uj)◊r*)
j=1
where N denotes the number of scenarios, uj denote the value of scenario j, and ◊ is the binary function such that a ◊ b = 1 iff a≥ b and a ◊ b = 0 otherwise.
For example, consider the two decisions d' and d'' whose respective performances are as follows:
d'
d''
ρ(d') = 28
ρ(d'') = 29
where the white dots represent scenarios that satisfy the performance requirement and gray dots represent scenarios that violate it.
In fact, it can prove effective to assign weights to scenarios, whereupon the robustness of decision d would be defined as follows:
N
ρ(d) :=
Σ
(r(d,uj)◊r*)·w(j)
j=1
where w(j) denotes the weight associated with scenario j.
Discussions on the importance of scenario selection for a proper representation of the complete region of uncertainty in robust optimization can be found in Rustem and Howe (2002) and Kouvelis and Yu (1997).
For new global approaches to robustness, see Ben-Tal et al (2006, 2009).
FAQ-46:Don't you miss the message and intent of the Info-Gap approach (eg. robustness of solutions and local nature of the analysis)?
Answer-46: Definitely not. I am not missing any Info-Gap message. I merely call a spade a spade.
The central issues here are of course "robustness" and the "localness" of the solutions obtained by Info-gap's analysis.
I fully accept that there are cases where no robust decisions can be obtained no matter what. Therefore, to expect Info-Gap, or for that matter any other methodology, to generate robust decisions for such cases would be naive, indeed unjustified.
But, this is not the point of my criticism. My criticism of Info-Gap decision theory is not that it may fail to deliver in certain (hard) cases. My criticism is that it is flawed methodologically. That is, that it cannot, as a matter of principle, be counted on to deliver, because, as I have been arguing all along, its approach to and definition of robustness are fundamentally flawed for decision-making under severe uncertainty. This, as I have shown, is due to its robustness model prescribing a local analysis which in effect amounts to ignoring the severity of the uncertainty.
Indeed, the contention (by Info-Gap proponents) that Info-Gap's analysis "can be helpful" — the implication being that "sometimes" it can deliver robust solutions — only brings out (in an amusing way) its dismal failure as a methodology. After all we do not bestow the title "methodology" on a "plan of attack" that all it can (half heartedly) say (and only when hard pressed) that it can (sometimes) deliver solutions. Such solutions are flukes and must be justified on a case by case basis.
In any event, the picture depicting Info-gap's approach is perfectly clear and no amount of rhetoric can change it:
No Man's Land
No Man's Land
U(α(d,û),û)
Safe
Info-Gap's local robustness analysis is what Info-Gap is all about and no amount of rhetoric about "Knightian Uncertainty" will make any difference:
No Man's Land
No Man's Land
U(α(d,û),û)
Safe
In short, Info-Gap's contention is crystal clear, you cannot miss it. It reads as follows:
wild guess ---->
Info-Gap Robustness Model
----> robust decision
α(d,û):= max {α≥0: r(d,u) ≥ r*, ∀u∈U(α,û)} , d∈D
û = wild guess of the true value of u.
My contention is therefore equally clear: a method propounding such contentions is fundamentally flawed.
FAQ-47:Can the fundamental flaws in Info-Gap decision theory be fixed?
Answer-47: I can't see how this can be done.
The only way to amend Info-Gap decision theory is to overhaul its domain of operation. That is, we would have to assume that the estimate û is of good quality, namely reliable, and that the true value of u is in the neighborhood of û.
This would mean in turn that we would have to redefine Info-Gap a Maximin methodology that is designed for decision-making under very mild uncertainty. However, this would fly in the face of Ben-Haim's (2007, p. 2) position:
Info-gap theory is useful precisely in those situations where our best models and data are highly uncertain, especially when the horizon of uncertainty is unknown. In contrast, if we have good understanding of the system then we don't need info-gap theory, and can use probability theory or even completely deterministic models. It is when we face severe Knightian uncertainty that we need info-gap theory.
In a word, to fix Info-Gap we would have to remove "severe" from "Severe Uncertainty", but in so doing we would remove Info-Gap's raison d'être.
FAQ-48:Does Info-Gap decision theory deserve the level of attention that you give it?
Answer-48: Indeed it does.
It is important to bring into full view and in the greatest detail the grave errors that afflict this theory, precisely because it is so woefully flawed. In other words, it is important to make it patently clear that this theory is flawed beyond repair.
This is important because my experience has shown that Info-Gap's profuse rhetoric seems to have an irresistible lure so that analysts/scholars who come to it from other disciplines (for instance, applied ecology and conservation biology, finance etc.) fall for its grand declarations and promises, without realizing that the facts that are buried under this rhetoric bespeak a different story altogether.
To appreciate this point and to illustrate my concern, consider the following recommendation quoted from a paper authored by nine senior scientists from four countries and published in the journal Ecological Modelling (Moilanen et al 2006, p. 124):
" ... In summary, we recommend info-gap uncertainty analysis as a standard practice in computational reserve planning. The need for robust reserve plans may change the way biological data are interpreted. It also may change the way reserve selection results are evaluated, interpreted and communicated. Information-gap decision theory provides a standardized methodological framework in which implementing reserve selection uncertainty analyses is relatively straightforward. We believe that alternative planning methods that consider robustness to model and data error should be preferred whenever models are based on uncertain data, which is probably the case with nearly all data sets used in reserve planning. ..."
I am particularly worried that PhD students and young researchers with minimal or no knowledge of Decision Theory may fall for the Info-Gap rhetoric and make it part of their research work.
I should also point out that my intensive investigation of Info-Gap is part of the research I am conducting in preparation for my forthcoming book provisionally entitled The Rise and Rise of Voodoo Decision Theories, where Info-Gap features as a classic example of such theories.
And finally, my work on Info-Gap is of course part of my Info-Gap Campaign to contain the spread of Info-Gap decision theory in Australia.
FAQ-49:Are there any Info-Gap software packages available?
Answer-49: I am not familiar with any such software packages.
However, I am aware of the software package called Zonation. It is promoted as a decision support tool for spatial conservation prioritization in the framework of large-scale conservation planning. One of its key features is that its uncertainty analysis is based on Info-Gap decision theory:
" ... In Zonation, uncertainty analysis has been implemented according to a convenient formulation that uses information-gap decision theory (see Ben-Haim 2006). ... "
Apparently users of this package of are not required to use Info-Gap's robustness model, so in this sense Zonation is not an Info-Gap package.
Remark:
I know for a fact that Zonation's developer, Atte Moilanen, is aware of the fact that Info-Gap's robustness model is a Maximin model and that Info-Gap's robustness model is unsuitable for decision-making under severe uncertainty.
These facts should therefore be mentioned/discussed in the Zonation User Manual. The reason that it is important that these facts be made explicit in the package is that the literature on the application of Info-Gap decision theory in applied ecology and conservation biology lays great stress on the fact that the uncertainty under consideration is severe.
FAQ-50:Are there any general purpose solution methods for the generic problem posed by Info-Gap's decision-making model?
Answer-50: No, and it is extremely unlikely that such methods can be developed.
The solution of the optimization problem posed by Info-Gap's generic decision-making model
α(û) =
max
{α: r(d,u) ≤ r*, ∀u∈U(α,û)}
d∈D
α≥0
is a problem-specific task.
It all depends on the specifications of the objects D, r, and U(α,û). In some cases it is very easy to solve the problem posed by the model, in others it is extremely difficult.
This explains why no general purpose software package for solving the optimization problem posed by Info-Gap's decision-making model are available (see FAQ-49).
The two Info-Gap books (Ben-Haim 2001, 2006) pay no attention whatsoever to this important aspect of the theory.
Remark
By completely divorcing itself from Optimization Theory, Info-Gap decision theory does not take advantage of methods and techniques that have been developed over the past 50 years for the solution of a variety of Maximin problems of this type.
FAQ-51:: From the standpoint of a Maximin algorithm, isn't the decision-variable α just a nuisance that can be handled by a line search?
Answer-51: Indeed it is.
In other words, consider Info-Gap's generic decision-making model:
α(û) =
max
{α: r(d,u) ≥ r*, ∀u∈U(α,û)}
d∈D
α≥0
and assume that for each α≥0 it is easy to solve the following Maximin problem:
Problem P(α,û): ρ(α,û) :=
max
min
r(d,u)
d∈D
u∈U(α,û)
Then Info-Gap's decision-making problem would be solved by a search for the largest value of α for which ρ(α,û) ≥ r*.
Of course, sometimes it is possible to solve the problem by simpler or more efficient solution methods. In such cases resorting to this rather crude solution technique can be obviated.
FAQ-52:What is your favorite example of an Info-Gap model/analysis in action?
Answer-52: I can cite a number of examples from the Info-Gap literature, illustrating how the flawed Info-Gap approach is applied to problems subject to severe uncertainty.
But it is difficult to pick a "favorite". When I decide, I'll discuss it here.
One of the major contenders at present is a rather simple Info-Gap model whose ingredients are as follows:
Decision space: D = {d',d''}.
Complete region of uncertainty: U=ℜ+:=[0,∞).
Regions of uncertainty: U(α,û):= {u∈U: |u-û|≤ α}, α≥0, where û >>>>>>> 0.
Robustness:
α(d',û):= max {α≥0: u ≤ r' , ∀u∈U(α,û)}, if û ≤ r' and α(d',û):= 0 otherwise.
α(d'',û):= max {α≥0: u ≥ r'' , ∀u∈U(α,û)}, if û ≥ r'' and α(d'',û):= 0 otherwise.
where r' and r'' are given positive numbers such that r'' ≥ r' >>>>> 0.
It is straightforward to show that
α(d',û) = r' - û , if û ≤ r'.
α(d'',û) = û - r'' , if û ≥ r''.
This means that we select decision d' if û ≤ r' and we select decision d'' if û ≥ r''. We "pass", namely do not select any decision, if r' < û < r''.
The great merit of this rather simple model --- according to Info-Gap experts --- is that it provides a reliable methodology for tackling a variety of very important practical forecasting problems that are subject to severe (true Knightian) uncertainty. That is, forecasting problems where the estimate û is unreliable due to the severe uncertainty in the true value of the parameter of interest.
You'll appreciate this point more fully when you learn what practical problems this model is said to solve. For the time being, let us keep the discussion abstract and describe the contention made by this Info-Gap model. To begin with let us be clear on the main outlines of the problem that this model takes on:
You have to determine which decision to select from D = {d',d''}, if any.
Your best choice hinges on the value of some parameter u whose true value, call it u*, is subject to severe (true Knightian) uncertainty.
The best strategy under certainty (assuming that we know the value of u*) is as follows:
If u* ≤ r' it is best to select d'.
If u* ≥ r'' it is best to select d''.
If r' < u* < r'' it is best to "pass".
You have a highly unreliable estimate of u*, call it û.
What should you do? Should you select d', d'' or "pass"?
Info-Gap's robustness analysis instructs you to adopt the following strategy, under which the choice between d', d'' and "pass" depends on the relationship between the estimate û and the values of r' and r'':
If û ≤ r', then select d'.
If û ≥ r'' then select d''.
If r' < û < r'', then "pass".
To give you better insight into the working of the Info-Gap methodology under consideration, let us compare its results to those yielded by an analysis conducted under Certainty. The picture is this:
Best Strategy under Certainty
If u* ≤ r' it is best to select d'.
If u* ≥ r'' it is best to select d''.
If r' < u* < r'' it is best to "pass".
Info-Gap's Strategy under Severe Uncertainty
If û ≤ r', then select d'.
If û ≥ r'' then select d''.
If r' < û < r'', then "pass".
As you can clearly see, Info-Gap's strategy under severe uncertainty is identical to the best strategy under certainty except that it uses the estimate û instead of the true (unknown) value u*.
So, the question obviously arises:
What is this big idea of using the Info-Gap methodology given that all that this methodology does here is to replace the true value u* by its estimate û in the formulation of the best strategy under certainty?
Why don't we simply say: assume that there is no uncertainty and pretend that u* is equal to û?
But there is a far more serious question that the proposed methodology gives rise to:
Given that the estimate û is highly unreliable, what guarantee is there that the proposed methodology is reliable?
That is, aren't we dealing here with a methodology that is based on the following unreliable premise?
highly unreliable estimate ---->
Model
----> reliable robust decision
The short answer is: Yes, of course we are! The proposed methodology is only as reliable as the estimate û.
In any event, according to these Info-Gap's experts, using this methodology would enable generating reliable decisions now for gold trading (d'="sell", d''="buy", u= price of gold) in the middle of next year! All we need for this purpose is an estimate (û) of the price of gold in the middle of next year. And the good news is that a rough, unreliable estimate will do!
Personal Note:
Had I had in my possession a reliable methodology for gold trading in the middle of next year, I would not have been writing this paragraph right now. Indeed, I would have kept it top secret.
To be continued ...
FAQ-53:
Will ardent Info-Gap proponents ever concede that Info-Gap's robustness and decision-making models are Maximin models?
Answer-53: Extremely unlikely.
For some years now -- at least since 1999 -- the thesis that Info-Gap's robustness model is not a Maximin model has been a fixture in the Info-Gap literature. This thesis has been part of the broader thesis that Info-gap is a novel/radical approach to decision making under uncertainty. So understandably, an admission to the contrary is no simple matter.
For consider what would a concession that Info-Gap's robustness model is a Maximin model amount to?
Such a concession will completely demolish Info-Gap's basic thesis that it is a new theory that is substantially different from all current theories for decision under uncertainty.
More importantly, it will call into question the validity of Info-Gap's many other (unsubstantiated) claims, and by association, the validity of the entire Info-Gap enterprise.
In short, there is a lot at stake here for Info-Gap decision theory: The debate on the Maximin/ Info-Gap connection is not just a technical discussion.
It is not surprising therefore that the stance adopted in Info-Gap is that of adhering to the Seventh Natural Law of Operations Analysis (see FAQ-54), namely extending an error is preferred to admitting a mistake.
In other words, the Info-Gap literature remains oblivious of the following clear-cut result:
Maximin Theorem (Sniedovich 2006b, 2007a, 2008a, 2008b, 2008c), WIKIPEDIA
α(d,û):= max {α: r(d,u) ≥ r*, ∀u∈U(α,û)} ≡
max
min
α·(r(d,u)◊r*)
α≥0
u∈U(α,û)
where a ◊ b := 1 iff a ≥ b and a ◊ b := 0 otherwise.
Instead, the opposite (erroneous) idea, namely that Info-Gap's robustness model is not a Maximin model, is being promoted.
But, as I have shown in Sniedovich (2008a), and discussed in FAQ-20, this misguided effort ends in a huge mathematical failure. For not only is the "result" wrong, the arguments on which this "result" are based exhibit grave misconceptions regarding the modeling of Wald's Maximin paradigm and worst-case analysis in general.
In other words, rather than take the bull by the horns and deal directly with the basic fact (Maximin Theorem) for what it is -- a mathematical statement about the relationship between two simple mathematical models -- a lengthy scholastic argument is put forward in support of an array of erroneous contentions.
But what is the outcome of this scholastic argument?
For one thing, it brings into full view, indeed exacerbates, the flaws in the arguments.
Consider for instance Ben-Haim's (2008) latest essay on the "differences/similarities" between Info-Gap robustness and Maximin. The technical and conceptual errors revealed here are so grave that I will have to take up some of them in subsequent FAQs.
To give you an idea of what I mean, consider the following:
" ...
Info-gap robust-satisficing is motivated by the same perception of uncertainty which motivates
the min-max class of strategies: lack of reliable probability distributions and the potential for severe
and extreme events. We will see that the robust-satisficing decision will sometimes coincide with a
min-max decision. On the other hand we will identify some fundamental distinctions between the
min-max and the robust-satisficing strategies and we will see that they do not always lead to the
same decision.
First of all, if a worst case or maximal uncertainty is unknown, then the min-max strategy cannot
be implemented. That is, the min-max approach requires a specific piece of knowledge about the
real world: "What is the greatest possible error of the analyst's model?". This is an ontological
question: relating to the state of the real world. In contrast, the robust-satisficing strategy does
not require knowledge of the greatest possible error of the analyst's model. The robust-satisficing
strategy centers on the vulnerability of the analyst's knowledge by asking: "How wrong can the
analyst be, and the decision still yields acceptable outcomes?" The answer to this question reveals
nothing about how wrong the analyst in fact is or could be. The answer to this question is the info-gap
robustness function, while the true maximal error may or may not exceed the info-gap robustness.
This is an epistemic question, relating to the analyst's knowledge, positing nothing about how good
that knowledge actually is. The epistemic question relates to the analyst's knowledge, while the
ontological question relates to the relation between that knowledge and the state of the world. In
summary, knowledge of a worst case is necessary for the min-max approach, but not necessary for
the robust-satisficing approach.
The second consideration is that the min-max approaches depend on what tends to be the least
reliable part of our knowledge about the uncertainty. Under Knightian uncertainty we do not know
the probability distribution of the uncertain entities. We may be unsure what are typical occurrences,
and the systematics of extreme events are even less clear. Nonetheless the min-max decision hinges
on ameliorating what is supposed to be a worst case. This supposition may be substantially wrong,
so the min-max strategy may be mis-directed.
A third point of comparison is that min-max aims to ameliorate a worst case, without worrying
about whether an adequate or required outcome is achieved. This strategy is motivated by severe
uncertainty which suggests that catastrophic outcomes are possible, in conjunction with a precautionary attitude which stresses preventing disaster. The robust-satisficing strategy acknowledges
unbounded uncertainty, but also incorporates the outcome requirements of the analyst. The choice
between the two strategies -- min-max and robust-satisficing -- hinges on the priorities and preferences
of the analyst.
The fourth distinction between the min-max and robust-satisficing approaches is that they need
not lead to the same decision, even starting with the same information.
..."
Ben-Haim (2008, p. 9)
A similar misguided discussion appears in Ben-Haim and Demertzis (2008, pp. 17-18).
The point to note first of all is that nowhere in this thesis is there any reference to the simple fact
Maximin Theorem (Sniedovich 2006b, 2007a, 2008a, 2008b, 2008c), WIKIPEDIA
α(d,û):= max {α: r(d,u) ≥ r*, ∀u∈U(α,û)} ≡
max
min
α·(r(d,u)◊r*)
α≥0
u∈U(α,û)
Equally disturbing is the explanation of the difference between Info-Gap and Maximin. This explanation demonstrates a profound lack of understanding and appreciation of the expressive power of Wald's Maximin model. For example, the claim that
"... In summary, knowledge of a worst case is necessary for the min-max approach, but not necessary for
the robust-satisficing approach. ...
is most revealing.
For not only is a priori knowledge of the worst case not necessary for the implementation of the Minimax model, it is precisely the task of the implementation of the Minimax model to "find" the best worst case.
For example, consider the following classic Minimax model, exhibiting one of the most famous saddle points on Planet Earth:
p :=
min
max
x2 - y2
x∈ℜ
y∈ℜ
ℜ = real line.
The implementation of this Minimax model yields the optimal solution, namely the best worst case with respect to the min player. It is the saddle point (x,y) = (0,0), yielding p=0. Note that the objective function here, namely the function f=f(x,y) defined by f(x,y)=x2 - y2, is unbounded on ℜ2.
So much then for the big idea that " ... knowledge of a worst case is necessary for the min-max approach ..."
To sum up:
Not only is it the case that Ben-Haim's conclusions are wrong, the arguments on which his conclusions are based are woefully misguided. In any event, the question of the relationship between Wald's Maximin model and Info-Gap's robustness and decision-making models is a technical one and must therefore be treated as such. No amount of scholastic rhetoric can change this basic fact:
Maximin Theorem (Sniedovich 2006b, 2007a, 2008a, 2008b, 2008c), WIKIPEDIA
α(d,û):= max {α: r(d,u) ≥ r*, ∀u∈U(α,û)} ≡
max
min
α·(r(d,u)◊r*)
α≥0
u∈U(α,û)
More details concerning the errors in Info-Gap's rhetoric on the relationship between Wald's Maximin model and Info-Gap's robustness model can be found in Sniedovich (2007a, 2008a, 2008b, 2008c).
For almost thirty years a copy of the following Ten-Laws hung in my office. I believe that this list is extremely relevant to the present discussion.
The Ten Natural Laws of Operations Analysis
Bob Bedow
DELEX Systems, INC.
8150 Leesburg Pike
Vienna, VA 22180
Ignore the problem and go immediately to the solution, that is where the profit lies.
There are no small problems only small budgets.
Names are control variables.
Clarity of presentation leads to aptness of critique.
Invention of the wheel is always on the direct path of a cost plus contract.
Undesirable results stem only from bad analysis.
It is better to extend an error than to admit to a mistake.
Progress is a function of the assumed reference system.
Rigorous solutions to assumed problems are easier to sell than assumed solutions to rigorous problems.
In desperation address the problems.
Source: Interfaces 7(3), p. 122, 1979.
You can figure out for yourself which items on this list apply to the case of Info-Gap.
FAQ-55:Don't Info-Gap proponents essentially argue that "anything goes" under severe uncertainty?
Answer-55: Indeed, they do.
This position is a direct consequence of their broader view as to what constitutes a scientific approach to decision-making. For instance, consider this statement in the Info-Gap article in WIKIPEDIA:
" ... It is correct that the info-gap robustness function is local, and has restricted quantitative value in some cases. However, a major purpose of decision analysis is to provide focus for subjective judgments. That is, regardless of the formal analysis, a framework for discussion is provided. Without entering into any particular framework, or characteristics of frameworks in general, discussion follows about proposals for such frameworks. ..."
In other words, under severe uncertainty the estimate is indeed a wild guess, therefore the result of a robustness analysis in the neighborhood of this estimate is unlikely to represent a decision's robustness relative to the complete region of uncertainty.
FAQ-56:In what sense is Wald's Maximin model much more powerful and general than Info-Gap's decision-making model?
Answer-56: The power of Wald's famous Maximin model is in its versatility. It gives the analyst the freedom to specify the objective function and the uncertainty space to faithfully reflect the problem's requirements.
This versatility is made clear in the manner in which it is expressed in Info-Gap's decision-making model whose two distinguishing characteristics are:
The objective function represents Info-Gap's performance requirement r(d,u)≥r*.
The uncertainty space represents Info-Gap's regions of uncertainty U(α,û),α≥0.
So borrowing Annie's inimitable line to Frank, Wald's Maximin model would contend: Anything you can do I can do better!
The picture is this:
General Maximin Model
v*:=
max
min
f(x,s)
x∈X
s∈S(x)
Info-Gap's Decision-Making Model
z*:=
max
min
α·(r(d,u)◊r*)
d∈D
u∈U(α,û)
α≥0
Observe that the Maximin model imposes no structure whatsoever on its state spaces S(x), x∈X whereas Info-Gap imposes the nesting property on its regions of uncertainty U(α,û), α≥0. Similarly, the Maximin model does not impose any structure on its objective function f=f(x,s), whereas Info-Gap induces a rather specific objective function, namely g(d,α,u)=α·(r(d,u)◊r*). Clearly, the Maximin framework is incomparably more versatile insofar as the flexibility in modeling is concerned.
In sum, this is another way of saying that Info-Gap's robustness and decision-making models are no more than specific instances of the mighty Maximin (see Sniedovich (2008c).
See FAQ-18 for more details on the relationship between Info-Gap's decision-making model and Wald's Maximin model.
FAQ-57: Do you plan to compile these FAQs into a book?
FAQ-58: On what grounds is it claimed that Info-Gap's robustness analysis and a Maximin analysis may yield different results?
Answer-58: Such erroneous claims -- which as we have seen, are advanced in support of the denial that Info-Gap's robustness model is an instance of Wald's Maximin model -- are based on a woefully misguided comparison of apples with oranges.
The point is this. Given that Wald's Maximin model is a general prototype model it necessarily subsumes countless special cases and instances one of which is Ben-Haim's Info-gap model. So, when setting out to conduct a comparison between Info-Gap's model and Wald's Maximin model one's first obligation is to make sure that the instance of Wald's Maximin model chosen for this purpose is appropriate (correct, right) for the comparison. But, this is precisely where Ben-Haim errors begins.
Ben-Haim's (2008, p. 9) claim
" ... The fourth distinction between the min-max and robust-satisficing approaches is that they need
not lead to the same decision, even starting with the same information. ..."
is an unfortunate error resulting from the choice of a wrong instance of Wald's Maximin model.
The correct instance of Wald's Maximin model is spelled out clearly by
Maximin Theorem (Sniedovich 2006b, 2007a, 2008a, 2008b, 2008c), WIKIPEDIA
α(d,û):= max {α: r(d,u) ≥ r*, ∀u∈U(α,û)} ≡
max
min
α·(r(d,u)◊r*)
α≥0
u∈U(α,û)
That is,
max
max {α: r(d,u) ≥ r*, ∀u∈U(α,û)} ≡
max
min
α·(r(d,u)◊r*)
d∈D
d∈D
u∈U(α,û)
α≥0
Hence, (d,α) is an optimal solution to Info-Gap's decision-making problem if and only if this pair is also an optimal solution to the max player in the Maximin model spelled out above. In short, if you construct the Maximin model according to the recipe spelled out by the Maximin Theorem, then Info-Gap and Maximin will yield the same optimal decisions.
To better understand how Ben-Haim's flawed argument works, consider the following presumably "challenging" argument that Ben-Haim's line of reasoning would use to "prove" that the generic linear equation bx + c = 0 is not an instance of the generic quadratic equation Ax2 + Bx + C = 0:
A linear equation and a quadratic equation may yield different solutions: for instance, 2x-1=0 yields x=1/2, whereas 2x-1-x2=0 yields x=1.
Does this means that the generic linear equation bx + c = 0 is not an instance of the generic quadratic equation Ax2 + Bx + C = 0 ?
Of course not!
The correspondence requires setting A = 0; B = b and C = c. If you erroneously set A=1, then the blame for the resulting mess is on you!
In other words, to properly model the generic linear equation as an instance of the generic quadratic equation you have to make sure that you use the correct instance of the latter. Likewise, to properly formulate Info-Gap's decision-making model as a Maximin model, you have to make sure that you use the correct instance (eg. the instance specified by the Maximin Theorem) of the latter.
As explained in FAQ-20, Ben-Haim's error is that instead of using the Maximin model stipulated by the Maximin Theorem, he uses (eg. Davidovitch and Ben-Haim 2008) an inappropriate Maximin formulation.
The full story is as follows:
Info-Gap's decision-making model
α(û) =
max
max {α≥0: r(d,u) ≥ r*, ∀u∈U(α,û)}
d∈D
Ben-Haim's Wrong Maximin model
Correct Maximin model
α(û;α'):=
max
min
r(d,u)
d∈D
u∈U(α',û)
α(û):=
max
min
α·(r(u,d) ◊ r*)
d∈D
u∈U(α,û)
α≥0
Note: α' is a prespecified positive number.
Note: a◊b =1 iff a≥b; a◊b =0 otherwise.
The correct Maximin model and Info-Gap's decision-making model are equivalent and both yield the same optimal solutions.
FAQ-59: Why do Info-Gap proponents persist in using the wrong Maximin formulation in their analysis of the relationship between Maximin and Info-Gap?
Answer-59: I have no explanation for this.
Since they are fully aware of the existence of the correct Maximin formulation and they do not question its validity as a proper representation of Info-Gap's decision-making model, it is indeed baffling.
It would appear that this saga continues because Info-Gap proponents try to maintain the myth that Info-Gap's robustness and decision-making models are not Maximin models. Perhaps.
FAQ-60: What PROBLEM does Info-Gap's decision-making MODEL actually represent?
Answer-60: This important FAQ brings to light one of Info-Gap's greatest methodological failings. It highlights the fact that it is actually unclear what problem does the Info-Gap methodology grapple with. What problem does Info-Gap seek to answer?
The point is this. When we conduct an investigation of a problem, be it for purely theoretical purposes, or for practical purposes or, for a combination of both, a crucial activity in this effort is the "mathematical modeling" of the problem concerned. The accepted practice while engaging in this activity is to distinguish between the problem that we aim to analyze/solve and the model that we use for this purpose. The reason for this distinction is simple. It is usually the case that the same problem can be described and analyzed by more than one model.
For example, consider the famous Traveling Salesman Problem (TSP). This problem can be formulated in various ways: by an Integer Programming (IP) model and by a dynamic programming (DP) model. So, while these models are utterly different from one another, they nevertheless describe the same generic TSP problem.
Now, in the case of Info-Gap, the distinction between the problem and the model is all but blurred, one might say non-existent. Confusion reigns in the Info-Gap literature as to what is the problem and what is the model. As a result, is it seldom clear what elements of a specific Info-Gap model are induced by the problem itself, and what elements are ingredients of the Info-Gap methodology, namely are not prescribed by the requirements of the problem itself. In a word, reading the Info-gap literature one is left wondering what problem does the Info-Gap methodology actually address.
So, to be able to identify Info-Gap's problem of concern we need to perform some detective work. To this end we shall adopt another good practice from the "world of mathematical modeling" whereby a distinction will also be drawn between two versions of the problem under consideration. That is, we shall distinguish between the problem expressing conditions of certainty and, its counterpart expressing conditions of uncertainty. The latter version will be viewed as the more complex counterpart of the former, the complication obviously arising from the uncertainty. With this as background, consider now the following:
Info-Gap's generic decision-making model
α(û) =
max
max {α≥0: r(d,u) ≥ r*, ∀u∈U(α,û)}
d∈D
Of interest to us here are two problems (versions) that are associated with this model:
The problem represented by this model.
The simplified version of the problem where we know the true value of u.
Setting off the problem (version) postulating certainty against the problem postulating uncertainty should give us insight into the complications caused by the underlying severe uncertainty. In other words, pitting one version against the other should enlighten us on why the uncertainty is represented in Info-Gap's formulation of its problem of interest, the way it is.
Now, when one reads the Info-gap literature with this juxtaposition in mind, it becomes abundantly clear that there is nothing in this literature to suggest that the idea of nesting the regions of uncertainty so as to "quantify" the uncertainty, is dictated by any special needs expressed by the problem in question. The problem itself calls only for a definition of a region of uncertainty meaning that all that it prescribes is the complete region of uncertainty U, and perhaps the estimate û of the true value of u. So clearly, the characteristic of nested regions of uncertainty is projected on the problem entirely by the Info-Gap methodology.
As for the formulation of the performance requirement in Info-gap's model description, namely r(d,u) ≥ r*. Again, reading the Info-Gap literature it emerges that there is a good deal of ambiguity as to the exact role of the constraint in this framework. Indeed, the constraint can be understood to impose two different requirements:
It is desired (albeit not always possible) to satisfy this constraint over the assumed complete region of uncertainty.
It is desired that r(d,u) be as large as possible -- yet "robust" against uncertainty in the true value of u.
It follows then that if we remove the uncertainty altogether -- by assuming that we know with certainty the true value of u, call it u* -- there are two problems to consider:
Complete Certainty
Optimization Problem
max {r(d,u*): d∈D}
Satisficing Problem
Find a d∈D such that r(d,u*) ≥ r*
The question then is:
What are the counterparts of these two problems if we assume that the value of u* is subject to severe uncertainty hence unknown?
This is the question that Info-Gap decision theory is in fact supposed to address.
But does it?
Let us see.
Suppose that when we move from the safety of the world of certainty to the obscure world of severe uncertainty, we nominate robustness to be our main concern so that consequently our goal is to select the most robust decision. Then the questions that we would seek to answer are these:
How should we define "robustness" in the framework of the Optimization Problem "max {r(d,u): d∈D}" where the true value of u is subject to severe uncertainty?
How should we define "robustness" in the framework of the Satisficing Problem "Find a d∈D such that r(d,u) ≥ r*" where the true value of u is subject to severe uncertainty?
Info-Gap's decision theory does not address the first question explicitly, and its answer to the second question is as follows:
Info-Gap's generic Robustness Model
α(d,û) =
max {α≥0: r(d,u) ≥ r*, ∀u∈U(α,û)} , d∈D
This, at best, is an answer to the wrong question.
For it is important to stress that the conundrum that conditions of severe uncertainty present us with is not that of finding the decision that is most robust in the neighborhood of a particular value of u, be that the "best estimate" or an arbitrary value of u. The challenge that we are facing is: how do we go about deciding which decision is the most robust with respect to u given that we have no clue as to the true value of u?
In short, the problem actually addressed by Info-Gap decision theory is this:
What is the most robust decision for the Satisficing Problem "Find a d∈D such that r(d,u) ≥ r*" in the neighborhood of the estimate û of the true value of u?
So, the point is that by a priori restricting the scope of robustness to the neighborhood of the estimate û, Info-Gap has already thrown severe uncertainty out of the window. Indeed, Info-Gap's definition of robustness is taken "as is" from Ben-Haim (1996), where the uncertainty is not assumed to be severe!
FAQ-61: How does Info-Gap decision theory distinguish between different levels of uncertainty?
Answer-61: It does not.
As brought out by the discussion in FAQ-13 through FAQ-17, the "localness" of Info-Gap's robustness analysis is due to the analysis focusing entirely on a point estimate û of the true value of the parameter of interest and its immediate neighborhood.
But this single minded concentration on the estimate and its immediate neighborhood in effect entails that the analysis does not discriminate between levels (severity) of the uncertainty. The same analysis is applied ad infinitum regardless of the uncertainty growing or diminishing, intensifying or lessening. This is illustrated in the picture below where complete regions of uncertainty (U', U'', U''') of various sizes are shown, all centered at the same estimate û.
where α'=α(û) +ε, for some ε>0.
Note that the analysis remains unchanged despite the uncertainty intensifying - the region of uncertainty growing from U' to U'', to U''' and so on.
To better appreciate this absurd, assume that your complete region of uncertainty is say U=[-1000,1000] and that your "best" estimate is û=0. Now, suppose that research and development enable a significant reduction in the size of the region of uncertainty. How will such a reduction affect the results of Info-Gap's robustness analysis? For instance, suppose that we can reduce U to say U'=[-500,500]. How will this affect the results of Info-Gap's robustness analysis?
The answer is that so long as the "best estimate" remains the same and U contains U(α',û), the reduction in the size of U will have no impact whatsoever on Info-Gap's robustness analysis.
This is the grounds for my contention that Info-Gap decision theory in fact does not deal with the severity of the uncertainty and for my defining it the way I do in FAQ-6.
FAQ-62: Isn't Info-Gap's uncertainty model superfluous in the one-dimensional case?
Answer-62: Yes, it is.
The primary function of Info-Gap's uncertainty model is to specify a one-dimensional measure of distance between the estimate û and other elements of U. So, to use it in the one dimensional case, that is when U is an interval of the real line, is utterly pointless because |u-û| can be used for this purpose.
Indeed applying Info-Gap's uncertainty model to the one dimensional case is not only utterly pointless, it is in fact counter-productive because it conceals the true facts obtained in the analysis. And yet surprisingly, Info-Gap experts do apply Info-Gap's uncertainty model to the one dimensional case.
To see what I am driving at note that if the performance function r is continuous with u, then the critical value of u -- the value beyond which the performance requirement is not satisfied -- is equal to one of the roots of the equation r(d,u) = r*, namely the root in U that is closest to û. If there are no such roots, then either no element of U satisfies the performance requirement, or all the elements of U satisfy this requirement. In the former case the robustness is equal to zero, in the latter it is unbounded.
In short, in the one dimensional case, Info-Gap's robustness analysis boils down to solving the equation r(d,u) = r*.
Remark:
Note that if for a given decision d∈D the equation r(d,u) = r* has a unique root in U, then the implication is that the critical value of u associated with d does not depend on the estimate û. The picture is this:
Since we assume that r(d,û)≥r*, it follows that uc is critical regardless of the specific value of û.
If r(d,u)=r* has more than one root in U, then the critical value of u is the root that is closest to û, and this of course depends on the value of û. The picture is this:
Here we have 5 roots in U. Which of those is the critical u depends on the location of û.
FAQ-63: What are the differences/similarities between Info-Gap's tradeoff curves and the famous Pareto Frontiers?
Answer-63: Info-Gap's tradeoff curves (between performance and robustness) are typical examples of the famous Pareto Frontier.
It is therefore utterly incomprehensible that no indication whatsoever is given in either edition (Ben-Haim 2001, 2006) of this fact. Both editions of the Info-Gap book burst with discussions (supported by curves) describing tradeoffs between robustness and performance yet, nowhere is it made clear that these are Pareto tradeoffs.
In fact, the term Pareto is not even listed in the subject index of these books.
It is important to call attention to this fact if only for the reason that -- as my experience has shown -- newcomers to the field have the impression that the idea of robustness/performance tradeoffs is an Info-Gap innovation.
FAQ-64: Can Info-Gap's generic tradeoff problem be formulated as a Pareto Optimization problem?
Answer-64: Indeed it can.
Info-Gap's tradeoff problem can be stated formally as follows:
Note that in practice it is often convenient to generate the Pareto Frontier for the Info-Gap tradeoff problems by solving the following parametric Maximin problem:
r*(α):=
max
min
r(d,u)
, α ≥ 0
d∈D
u∈U(α,û)
The Pareto frontier consists of all pairs (α,r*(α)), α≥0.
FAQ-65: What exactly is "Knightian Uncertainty" and in what way is it different from "conventional" uncertainty?
Answer-65: To answer this question I shall have to take a closer look at the concept of uncertainty and its affiliated terminology. It is important to make clear from the outset, though, that the epithet "Knightian" is no more than a stand-in for "Severe". So the constant recitation of the term "Knightian Uncertainty" (in the Info-Gap literature) to highlight the severity of the uncertainty has the effect of turning it into a mere buzzword.
The epithet "Knightian" is due to the economist Frank Hyneman Knight (1885-1972) -- one of the founders of the so-called "Chicago school of economics" -- who is credited with the distinction between "risk" and "uncertainty".
Recall that classical decision theory distinguishes between three levels of knowledge pertaining to a state-of-affairs, namely
Certainty
Risk
Uncertainty
The "Risk" category refers to situations where the uncertainty can be quantified by standard probabilistic constructs such as probability distributions.
In contrast, the "Uncertainty" category refers to situations where our knowledge about the parameter under consideration is so meager that the uncertainty cannot be quantified even by means of an "objective" probability distribution.
The point is then that "Uncertainty" eludes "measuring". It is simply impossible to provide a means by which we would "measure" the level, or degree, of "Uncertainty" to thereby indicate how great or daunting it is. To make up for this difficulty a tradition has developed whereby the intensity of the "Uncertainty" is captured descriptively, that is, informally through the use of "labels" such as these:
Strict uncertainty
Severe uncertainty
Extreme uncertainty
Deep uncertainty
Substantial uncertainty
Essential uncertainty
Hard uncertainty
Hight uncertainty
True uncertainty
Fundamental uncertainty
Wild uncertainty
Knightian uncertainty
True Knightian uncertainty
Severe Knightian uncertainty
The trouble is, however, that all too often, these terms are used as no more than buzzwords with a web of empty rhetoric spun around them. So, to guard against this, it is important to be clear on their meaning in the context of the problem under consideration.
In this discussion I prefer to use the term "Severe Uncertainty". I understand "Severe Uncertainty" to connote a state-of-affairs where uncertainty obtains with regard to the true value of a parameter of interest. That is, the true value of this parameter is unknown so that the estimate we have of this true (correct) value is:
A wild guess.
A poor indication of this true (correct) value.
Likely to be substantially wrong.
According to some of my colleagues, "true" severe uncertainty can also entail that the estimate of the true value of the parameter of interest is based on
Intuition
Gut feeling
Rumors
So, as you can see, decision under severe uncertainty entails dealing with extreme situations where the estimates used are based on the flimsiest grounds even ... rumor!
This, needless to say, is a formidable challenge, especially if the stated goal (as in the case of Info-gap) is to provide robust decisions.
To return then to the origins of the term "Knightian Uncertainty", here is Knight's description of the difference between "Risk" and "Uncertainty":
To preserve the distinction which has been drawn in the last chapter between the measurable uncertainty and an unmeasurable one we may use the term "risk'' to designate the former and the term "uncertainty'' for the latter. The word "risk'' is ordinarily used in a loose way to refer to any sort of uncertainty viewed from the standpoint of the unfavorable contingency, and the term "uncertainty'' similarly with reference to the favorable outcome; we speak of the "risk'' of a loss, the "uncertainty'' of a gain. But if our reasoning so far is at all correct, there is a fatal ambiguity in these terms, which must be gotten rid of, and the use of the term "risk'' in connection with the measurable uncertainties or probabilities of insurance gives some justification for specializing the terms as just indicated. We can also employ the terms "objective'' and "subjective'' probability to designate the risk and uncertainty respectively, as these expressions are already in general use with a signification akin to that proposed.
The practical difference between the two categories, risk and uncertainty, is that in the former the distribution of the outcome in a group of instances is known (either through calculation a priori or from statistics of past experience), while in the case of uncertainty this is not true, the reason being in general that it is impossible to form a group of instances, because the situation dealt with is in a high degree unique. The best example of uncertainty is in connection with the exercise of judgment or the formation of those opinions as to the future course of events, which opinions (and not scientific knowledge) actually guide most of our conduct.
Knight (1921, III.VIII.1-2)
Personally, I prefer the following characterization of uncertainty. It is taken from a paper by the famous British economist John Maynard Keynes (1883 - 1946), whose "Keynesian economics'', had a major impact on modern economic and political theory.
By "uncertain" knowledge, let me explain, I do not mean merely to distinguish what is known for certain from what is only probable. The game of roulette is not subject, in this sense, to uncertainty; nor is the prospect of a Victory bond being drawn. Or, again, the expectation of life is only slightly uncertain. Even the weather is only moderately uncertain. The sense in which I am using the term is that in which the prospect of a European war is uncertain, or the price of copper and the rate of interest twenty years hence, or the obsolescence of a new invention, or the position of private wealth owners in the social system in 1970. About these matters there is no scientific basis on which to form any calculable probability whatever. We simply do not know. Nevertheless, the necessity for action and for decision compels us as practical men to do our best to overlook this awkward fact and to behave exactly as we should if we had behind us a good Benthamite calculation of a series of prospective advantages and disadvantages, each multiplied by its appropriate probability, waiting to be summed.
Keynes (1937, pp. 213-5)
In sum, the term "knightian" does not connote conditions of uncertainty that are more exacting or, forbidding or, whatever, than those conveyed by the term "severe". Furthermore, the constant recitation of the term "Knightian Uncertainty" in the Info-Gap literature should not be interpreted as suggesting that Info-Gap in fact has the capabilities to deal with this uncertainty.
FAQ-66: Do you know of any convincing example where the Info-Gap complete region of uncertainty is unbounded?
Answer-66: No, I don't.
But I know of many unconvincing examples. In fact, all the examples I have found in the Info-Gap literature are unconvincing.
It suffices to mention two.
Example 1: Project Scheduling
In the project scheduling problem described in Ben-Haim (2006, pp. 64-70) the unknown parameter of interest is the list of N=16 duration times of some given tasks. The nominal durations of the tasks vary from 1 to 6 and the prescribed critical completion time of the entire project, tc, varies from 21 to 30.
Note that if the duration of a task is longer than tc, the performance requirement is violated. Hence, in this example, task durations larger than say 30.01 would not even come into the picture.
Yet, the complete region of uncertainty defined in this case (Ben-Haim 2006, pp. 64-70) is unbounded.
Example 2: Do foragers Optimize or Satisfice?
In the foraging problem studied in Carmel and Ben-Haim (2005) the unknown parameter is the rate of gain in energy (joules/minute) for a foraging animal in a given patch.
Carmel and Ben-Haim (2005, p. 635) propose an unbounded complete region of uncertainty for this parameter.
I must admit that I am no expert on the energy consumption of foraging animals, but I am confident that it is far more realistic to assume that the region of uncertainty under consideration is bounded (above and below) rather than unbounded.
Furthermore, I am confident that experts in this area can provide reasonable bounds for the complete region of uncertainty.
If hard pressed, I would argue that the bounded interval say G=[-1000000,1000000] is far more realistic than the interval (-∞,∞) proposed by Carmel and Ben-Haim (2005).
The issue here is not whether it makes sense to define an unbounded region of uncertainty in cases where a bounded region of uncertainty will do. The issue here is -- as I explain in FAQ-26 and FAQ-36 -- that the very idea of positioning the Info-Gap analysis in an unbounded region of uncertainty makes a mockery of this analysis as it exposes it to the following absurd:
No Man's Land
û
No Man's Land
Safe Sub-region
-∞ <-----------------
Complete region of uncertainty
-----------------> ∞
............................
No amount of rhetoric can undo the idea conveyed by this picture.
FAQ-67:Can't Info-Gap's "localness" flaw be fixed by means of a robustness analysis at a number of different estimates spread over the complete region of uncertainty?
Answer-67: No it cannot.
Suppose that we adopt this prescription and we conduct Info-Gap's robustness analysis k times using k different estimates, û(1),...,û(k). We would then end with k (potentially different) optimal decisions, d*(1),...,d*(k), to reckon with. How would we decide which decision to select?
In other words, instead of resolving the "localness" of Info-Gap's robustness analysis, this attempted "rescue operation" brings out more forcefully how deep rooted and intractable a failure it is. The failure here is intractable because the basic approach to severe uncertainty is flawed. It fails to recognize that the real difficulty posed by the true value being subject to severe uncertainty is that for each value of the parameter there is (potentially) a different optimal decision.
So, modifying Info-Gap's robustness analysis by means of the above prescription would require that the modified analysis be additionally backed up by a theory prescribing the selection of decisions under conditions of ... severe uncertainty. But this of course would require dealing with the following two issues:
Scenario generation
How to select the different estimates (scenarios) in a manner insuring that the complete region of uncertainty is properly represented?
Scenario resolution
How to resolve the difficulty of choosing the "best" decision out of the results obtained from the different scenarios?
In short, modifying Info-Gap's robustness analysis by means of the above prescription will be tantamount to re-inventing the well established fields of scenario optimization (eg. Dembo 1991) and robust optimization (eg. Kouvelis and Yu, 1997).
Remark:
It is interesting to note that Info-Gap experts are aware of the difficulties associated with scenario generation and analysis:
"... In recent years Rob Lempert and Steve Bankes at the RAND Corporation have developed computer-intensive simulation models for analysing the possible outcomes of policy decisions over large spaces of possible futures. The approach recognises the deficiencies in any model of a complex system and does not attempt to represent the
uncertainties in probabilistic terms. Rather, the approach, which the team at RAND refer to as 'Robust Decision Making', is based upon identifying options that perform acceptably well over the widest subset of the space of possible futures. The problem still remains, however, of specifying the range of that space of possibilities. Actually, if decision makers and their analysts know anything, it is about the central tendencies, not the bounds of variation. ..."
Hall and Ben-Haim (2007)
Does this explain the lack of any discussion on "Scenario Analysis" in the Info-Gap books (Ben-Haim 2001, 2006) and the absence of this topic from the subject indices?
Aren't Hall and Ben-Haim (2007) grossly inconsistent here?
While raising concerns about the specification of the "range of that space of possibilities" and the difficulties in specifying the "bounds" of this space, it does not even occur to them that Info-Gap's local approach to scenario generation might be incomparably more problematic!
In other words, Hall and Ben-Haim (2007) are perfectly happy with Info-Gap's local scenarios completely ignoring the severity of the uncertainty under consideration and the huge No Man's Land that the method generates:
Scenario Analysis a la Info-Gap
No Man's Land
û
No Man's Land
Safe Sub-region
-∞ <-----------------
Complete region of uncertainty
-----------------> ∞
..............................
No amount of rhetoric can "reinterpret" this picture.
FAQ-68:What exactly is behind Info-Gap's claim that decisions designed solely to optimize performance have no robustness?
Answer-68: Mostly rhetoric.
Info-Gap decision theory advances the view that under conditions of severe uncertainty maximizing the robustness of decisions is superior to maximizing the "reward" yielded by them. So as might be expected, when two decisions are compared, one that maximizes reward and another that maximizes robustness, the former may not necessarily be robust according to Info-Gap's definition of robustness.
Of course, one can argue that the decision that maximizes robustness does not necessarily generate a good level of "reward".
But this is hardly surprising: If x is an optimal solution to Problem A and y is an optimal solution to Problem B then we neither expect x to be a good solution to Problem B, nor y to be a good solution to Problem A. And why should we? After all, we compare the performance of solutions obtained for two different problems!
Why should we be surprised to learn that a solution found for Problem A does not perform well in the context of Problem B, and vice versa?
In short, the thesis that maximizing robustness is superior is a shibboleth that may seem sensible at first sight especially when it is accompanied with high-flown rhetoric. But it does not withstand the slightest scrutiny. I discuss this issue in connection with the Optimizing vs Satisficing debate.
I fully sympathize with Odhnoff's (1965) frustration:
It seems meaningless to draw more general conclusions from this study than those presented in section 2.2. Hence, that section maybe the conclusion of this paper. In my opinion there is room for both 'optimizing' and 'satisficing' models in business economics. Unfortunately, the difference between 'optimizing' and 'satisficing' is often referred to as a difference in the quality of a certain choice. It is a triviality that an optimal result in an optimization can be an unsatisfactory result in a satisficing model. The best things would therefore be to avoid a general use of these two words.
Jan Odhnoff On the Techniques of Optimizing and Satisficing
The Swedish Journal of Economics
Vol. 67, No. 1 (Mar., 1965)
pp. 24-39
Now back to the matter at hand.
Consider the following two problems:
Problem A
Problem B
z*(û):=
max
r(d,û)
d∈D
α(û):=
max
max {α≥0: r(d,u) ≥ r*, ∀u∈U(α,û)}
d∈D
Note that Problem B is Info-Gap's generic decision-making model.
You do not have to be an expert on optimization theory to figure out that the two problems are utterly different, so that an optimal solution to say Problem A is unlikely to be optimal for Problem B.
In particular, if we let r* = z*(û), then clearly the Info-Gap robustness of an optimal solution to Problem A would most likely be equal to zero, recalling that the robustness of decision d according to Info-Gap is equal to
α(d,û):= max {α≥0: r(d,u) ≥ r*, ∀u∈U(α,û)}
To see why this is so, substitute r* = z*(û) in this expression. This yields,
α(d,û):= max {α≥0: r(d,u) ≥ z*(û), ∀u∈U(α,û)} , d∈D
Now let dA be any optimal solution to Problem A. Then α(dA,û) > 0 only if r(dA,u) = z*(û) for all u ∈U(α',û), where α'=α(dA,û). Otherwise, α(dA,û) = 0.
So what?
The same is true for any decision d∈D, including the decision that is generated by Info-Gap decision-making model -- and this, mind you, is the case regardless of what specific value of r* is used.
Observe that this does not mean that the optimal decision to Problem A has zero robustness if r* < z*(û).
In short, the claim that decisions designed solely to optimize performance have no robustness are meaningless unless the critical performance level r* is specified:
If r* < z*(û) then this claim is groundless and is typically wrong (see FAQ-69).
If r* = z*(û) then this claim is correct but ... does not mean anything (see FAQ-69).
Therefore, statements such as
"... Attempting solely to optimize energy intake may endanger the animal because a maximal energy-intake strategy has zero robustness to info gaps. ..."
Carmel and Ben-Haim (2005, p. 639)
and
"... maximal utility is invariably accompanied by zero robustness. ..."
Ben-Haim (2006, p. 295)
are at best misguided.
Unfortunately, they are also misleading, as they omit to specify the assumed value of r* and the fact that for the value of r* for which the claim is valid, all other decisions are in the same boat.
Remarks:
The fact that the model "z*(û):= max {r(d,û): d∈D}" is used to determine what decision d should be used, does not mean that the reward z*(û) is expected to be realized -- especially under conditions of severe uncertainty.
Furthermore, if your interest is in the values of u in some set V⊂U, you can use the following robust optimization model:
max
r(d,û) subject to r(d,u)≥r',∀u∈V
d∈D
where r' is your preferred threshold performance level on V.
FAQ-69:Can you give a counter-example to the claim that decisions that optimize performance have no robustness to info-gaps?
Answer-69: Indeed I can.
In fact this is an extremely easy task because it gives expression to what is the rule rather than the exception.
Consider for instance the Info-Gap model where
Complete uncertainty region:
U = [0,∞)2
Decision space:
D = {(d1,d2): d1+d2 = 10, d1,d2≥0}
Performance function:
r(d,u) = d1u1 + d1u1
Regions of uncertainty:
U(α,û)={u∈U: (u1 - û1)2 + (u2 - û2)2 ≤ α2}
Best estimate: û=(6,5)
Critical performance level: r* = 30
The optimal solution to the "performance optimization problem"
z*(û):=
max
r(d,û)
d∈D
is d'=(10,0), yielding a reward of r'= r(d',û) = 60.
The robustness of this decision -- according to Info-Gap -- is as follows:
So clearly, the robustness of d' is not equal to zero.
Furthermore, observe that the most robust decision according to Info-Gap is d''=(6,4), yielding a reward of r''= r(d'',û) = 56 and robustness α(d'',û)=131/2=3.6055551275464.
Here, then, is the picture, where "safe" means that the performance requirement is satisfied:
d' = Performance Optimization Decision
d''= Optimal Info-Gap Robustness Decision
r* = 30
Robustness of decision d'=(10,0) which maximizes the reward r(d,û), yielding r(d',û)=60 and α(d',û)=3.
r* = 30
Robustness of the decision d''=(6,4) that maximizes the robustness α(d,û), yielding r(d'',û)=56 and α(d'',û) = 3.6055551275464.
Needless to say, the picture is utterly different if we change r*=30 to r*=60.
r* = 60
The robustness of decision d'=(10,0) which maximizes the reward r(d,û) is equal to zero. This decision satisfies the performance requirement r(d,û)≥r*.
r* = 60
The robustness of the decision d''=(6,4) that maximizes the robustness α(d,û) is equal to zero. Note that this decision does not satisfy the performance requirement r(d,û)≥r*.
As an aside, I should point out that it is not at all clear in what sense is d'' a priori superior to d' as claimed by Info-Gap decision theory.
FAQ-70:On what grounds does Info-Gap decision theory claim that utility maximization is entirely unreliable?
Answer-70: Who knows?
Info-Gap decision theory contends that under severe uncertainty maximizing robustness is superior to maximizing performance (utility). So, its decision model calls for the maximization of robustness subject to a performance requirement (constraint).
Indeed, one of the arguments that Info-Gap decision theory puts forward to promote itself is that maximization of utility is unreliable (Ben-Haim 2006, p. 295):
"... maximal utility is invariably accompanied by zero robustness. Utility-maximization is entirely unreliable. ..."
Of course, this is absurd.
If robustness is a factor, then one would maximize performance (utility) subject to a robustness constraint (requirement). In other words, the maximization of utility does not automatically preclude the incorporation of robustness requirements in the optimization model. In fact, this is routine in robust optimization.
And so, not only is the global claim (eg. Ben-Haim 2006, p. 295) "utility maximization is entirely unreliable" itself "entirely unreliable", it is in fact risible.
This, of course, is due to the kind of robustness that is prescribed by Info-Gap itself. The irony here is that it is precisely Info-Gap's robustness that is entirely unreliable under conditions of severe uncertainty. This is due to the local nature of Info-Gap's robustness model (see FAQ-13 - FAQ-17). The picture is this:
Reliability a la Info-Gap
No Man's Land
û
No Man's Land
Safe Sub-region
-∞ <-----------------
Complete region of uncertainty
-----------------> ∞
..............................
No amount of rhetoric can explain away the facts expressed by this picture.
FAQ-71:Can you elucidate your sketch of Info-Gap's "No Man's Land" Syndrome?
Answer-71: Certainly.
I created this sketch to explain in a non-technical manner the fundamental flaw in Info-Gap's robustness model. It is a variation of the Treasure Hunt sketch that I use for the same purpose. So, recall that the tale of the Treasure Hunt runs as follows:
Treasure Hunt
The island represents the complete region of uncertainty under consideration (the region where the treasure is located).
The tiny black dot represents the estimate of the parameter of interest (estimate of the location of the treasure).
The large white circle represents the region of uncertainty pertaining to info-gap's robustness analysis.
The small white square represents the true (unknown) value of the parameter of interest (true location of the treasure).
So, basing our search plan on Info-Gap Decision Theory, we may zero in on the neighborhood of downtown Melbourne, while for all we know, the true location of the treasure may well be in the Middle of the Simpson desert, or perhaps just north of Brisbane.
Perhaps.
Now, let us have a look at the No Man's Land sketch:
Info-Gap's No Man's Land Syndrome
No Man's Land
û
No Man's Land
Safe Sub-region
-∞ <-----------------
Complete region of uncertainty
-----------------> ∞
..............................
No amount of rhetoric can cover up the facts expressed by this picture.
Explanation:
The thick solid line represents Info-Gap's complete region of uncertainty, U. In this sketch this line goes from -∞ to ∞ because according to Ben-Haim (2006, p. 210) most of the commonly encountered Info-Gap models are unbounded.
This line indicates that the uncertainty is severe: the true value of the parameter of interest can be anywhere on this line. But what is more, we have not the slightest clue as to what sections of the line are more/less likely to contain the true value of the parameter.
The small red segment of the line represents the "safe" area generated by Info-Gap's robustness analysis. It is the largest region of uncertainty around the estimate û on which the performance requirement is satisfied.
Info-Gap proponents complain that I always depict a minutely small "safe" area relative to the very long black line depicting the No-Man's Land.
The point of course is that my graphic depiction of this idea is not done in jest, nor arbitrarily, nor carelessly, nor for whatever other reason. This is a faithful description of the predicament of Info-Gap's robustness model. It is dictated by the assumptions underlying this model, hence gives full expression to the mathematical consequences arising from them.
The No Man's Land consists of the two sections of the thick line on both sides of the red "safe" segment.
They represent that segment of the complete region of uncertainty -- which in effect amounts to most of it -- that does not impact on Info-Gap's robustness analysis.
In particular, that segment where Info-Gap's robustness analysis remains invariant to the different values of u that the performance function takes in this area.
So what is the point that is made by this sketch?
The point is crystal clear:
Info-Gap's robustness analysis is utterly unreliable because it is conducted only on a tiny section of the complete region of uncertainty.
Differently put, Info-Gap's robustness is a local property, representing the performance of decisions in the neighborhood of the estimate û. It does not represent robustness with respect to the complete regions of uncertainty.
Since the whole point in severe uncertainly is the unknown location of the true value of the parameter of interest, it follows that a robustness analysis that is confined to the neighborhood of Info-Gap's "safe" sub-region -- or for that matter, any other sub-region -- is unreliable.
It is akin to taking soil samples or measuring the temperature in the neighborhood of Melbourne, when the complete region of interest is Australia.
Of course, when one examines this obviously flawed idea as depicted by this sketch, the question that immediately springs to mind is how can such an idea be formulated at all.
And the answer to this is simple as it is well documented. The origins of this idea are to be found in a muddled approach to uncertainty, where the same treatment is accorded to "severe" uncertainty as to say "very mild" uncertainty. More precisely where a "bad estimate" is treated as though it were a "nominal value".
The point is not that Info-Gap's robustness model originated in "Robust Reliability in the Mechanical Sciences" (Ben-Haim, 1996) where the terms "severe uncertainty" and "Knightian uncertainty" are not so much as mentioned and where no indication is given that the uncertainty under consideration is severe. Rather, the point is that in Ben-Haim (1996), right from the outset, reliability is defined in terms of a safe deviation from a given nominal value:
"... In this book, reliability is assessed in terms of robustness to uncertain variation. The system or model is reliable if failure is avoided even when large deviation from nominal conditions occur. On the other hand, a system is not reliable if small fluctuations can lead to unacceptable performance. ..."
Ben-Haim (1996, p. 6)
The picture then is this, where û denotes the nominal value of the parameter of interest:
Info-Gap Reliability Model (1996)
û
Safe Sub-region
<-----------------
Complete region of uncertainty
----------------->
..............................
So, here we are concerned not with the uncertainty in û but with the value of u -- which is treated as a given nominal value
In contrast, in Ben-Haim (2001, 2006) the difficulty stems from the fact that the estimate û is "bad" and is likely to be "substantially wrong".
In short:
The 1996 version of the assumed problem has nothing to do with severe uncertainty -- it is all about a safe deviation from a given nominal value.
The 2001/2006 version of the assumed problem is all about severe uncertainty -- it has got nothing to do with a safe deviation from a given nominal value.
Of course, the trouble is that Ben-Haim (1996, 2001, 2006) prescribe the same methodology for both cases. This methodology, although suitable for the 1996 version of the problem, is utterly unsuitable for the 2001/2006 version.
Remarks:
The problem considered in Ben-Haim (1996) is "variability from a given point" type of problem. The fact that the variability is due to uncertainty is of little -- indeed no -- consequence.
My main criticism of the methodology proposed in Ben-Haim (1996) for the treatment of a safe deviation from a given nominal value is its not being recognized for what it is: Maximin.
FAQ-72:What is the difference between "robustness to deviation from a given (nominal) value" and "robustness to severe uncertainty"?
Answer-72: This is a very relevant question. It brings out the great confusion in the Info-Gap literature about the similarities/differences between these two concepts.
The issue here is basically about the range of values that a parameter can take and what this range represents in the framework of robustness analysis. To clarify this point, we need to distinguish between two thoroughly different states-of-affairs:
Certain variability
Uncertain fixed value
In the case of "certain variability" we know with certainty that the value of a parameter of interest will vary within a specified range. That is, we know that the parameter will take all the values it can within this pre-specified range. The task then is to evaluate our decisions according to this variation in values.
In contrast, in the case of an "uncertain fixed value" it goes without saying that the range does not signify a possible variation in the parameter's values. Rather, the specified range represents the fact that there is a complete lack of knowledge as to the exact value that the parameter has or can take within this range.
For instance, consider the following two cases describing, the endurance test of a car relative to speed (km/hr):
Test 1: Varied but known: You conduct a test where a car is driven for 2 hrs according to a prescribed pattern of varied speeds (km/hr) in the range [80,140].
Test 2: Fixed but unknown: You plan to conduct a test whereby a car will be driven at a fixed constant speed (km/hr) for 2 hrs, but the speed is unknown and its value is subject to severe uncertainty. That is, all that is known, at present, is that the fixed constant speed will be in the range [80,140].
Here is the picture:
Certain Variability
Uncertain Fixed Value
Range=[80,140]
Range=[80,140]
The difference between these two cases is clear so it requires no further elucidation:
In Test 1 the parameter "speed" actually takes infinitely many values. That is, its value varies over the entire range [80,140].
In Test 2 the parameter "speed" can take any value in the range [80,140]. But, the point is that this value is subject to severe uncertainty. Hence it is unknown what this value will actually be.
We shall consider the case where "certain variability" is expressed as a "deviation from a given nominal value". For instance, we shall represent the range [80,140] as a deviation from the given value vn=110, namely the range is expressed as [vn - 30 , vn + 30], where vn represents the "nominal" value (speed).
So as you can see, the notion of the "robustness of a car to speed" can have different meanings which are answers to two totally different questions:
How much can I deviate from the nominal speed vn in Test 1 without violating a prescribed performance requirement?
How robust is the car to speed in Test 2 subject to a prescribed performance requirement?
To throw more light on the difference between the two questions hence the different answers, let us consider the following simple example.
You need to replace the old climate control system in your greenhouse. The main function of this system is to control the temperature, t, in the greenhouse. Several products in the market fit the bill so, your task is to decide which of these suits your needs best.
I shall describe two versions of this problem.
The first version is about an "uncertainty-free" problem where, all that needs to be known about the parameters of the problem is indeed known, including the temperature t. The second version is about an utterly different situation. Here, the true value of t is unknown as it is subject to severe uncertainty.
Version 1: Robustness to deviation from a given nominal value.
The new climate control system will be used in a strawberry greenhouse where the nominal temperature, tn, is known. The new system must maintain the temperature in the greenhouse at this level. However, the system must also be able to cope well with deviations from this nominal value, and preference will be given to systems that can cope well with large deviations -- subject to a performance requirement.
Let
s∈S denote the system under consideration.
t denotes the temperature in the greenhouse.
tn denote the nominal temperature in the greenhouse.
h(s,t) ≥ h* represent the performance requirement for system s and temperature t.
To evaluate system s, the criterion that you may use for this purpose would determine the largest deviation in t from the given nominal value tn that still satisfies the requirement h(s,t) ≥ h*. Thus, you would define the robustness of system s as follows:
α(s):=
max
{α≥0: h(s,t) ≥ h*, ∀t∈U(α,tn)}
where U(α,tn)={t: |t-tn|≤α}.
The robustness that is being sought here has got nothing to do with uncertainty. That is, robustness is not directly driven, or motivated, or required, by the fact that there is uncertainty as to the parameter of interest. For, the important thing to note here is that tn is not an estimate of an unknown parameter. Rather, tn is a given known quantity that is used as a "reference point". This is not to say, of course, that uncertainty in the process governing the temperature t in the greenhouse can be a reason for seeking robustness. The point here is that robustness is evaluated in terms of the deviation of t from tn.
Version 2: Robustness to severe uncertainty in the true value of the parameter.
You plan to install a new climate control unit in your old square-watermelons greenhouse. The difficulty is that for various reasons you must purchase the unit without delay.
This means that your decision as to what control unit to purchase must be taken without knowing the prospective crop in greenhouse, hence the required nominal temperature that the unit will have to maintain.
Moreover, the huge success of the your square-watermelons project, impels you to consider a variety of exotic options -- including a miniature pink polar bear. In short, as things stand, the required nominal temperature related to prospective projects in the greenhouse is subject to severe uncertainty.
Let:
s∈S denote the decision variable (climate control unit).
t denote the required, fixed, future temperature in the greenhouse.
h(s,t) ≥ h* represent the performance requirement for system s and temperature t.
Note that the climate control unit is required to keep the temperature in the greenhouse at a fixed constant level and that the true value of this level is subject to severe uncertainty hence, unknown.
Again, to select the most appropriate climate control unit, you would need to evaluate it with respect to the range of temperatures that the unit can maintain. The question is then: What is a proper definition for robustness against the severe uncertainty in the true value of t in this case?
If you are an Info-Gap enthusiast, you may be tempted to set up the following robustness model for unit s:
α(s,tw):=
max
{α≥0: h(s,t)≥h*, ∀t∈U(α,tw)}
where tw is a wild guess of the true value of t and U(α,tw)={t: |t-tw| ≤ α}.
Clearly, the robustness models of the two versions of the problem are identical except for the use of the symbols tn and tw.
However:
The robustness model of Version 1 makes perfect sense as it measures the robustness in terms of a deviation from a given (nominal) point, tn.
But, the robustness model of Version 2 is utterly senseless as it measures "robustness" in terms of a deviation from the wild guess, tw, whereas it should have sought robustness against severe uncertainty in the true value of t.
So, as I have been arguing all along, the flaw in the robustness model of Version 2 is in the fact that rather than take on the uncertainty in the true value of t, it focuses on the neighborhood of the wild guess tw. The picture is this:
Robustness a la Info-Gap
No Man's Land
tw
No Man's Land
Safe Sub-region
<-----------------
Complete region of uncertainty
----------------->
..............................
No amount of rhetoric can explain away the facts expressed by this picture.
In summary:
In Version 1, focusing on the neighborhood of tn is precisely what needs to be done because ... our aim is to determine the largest deviation from the nominal value tn without violating the performance requirement.
But, focusing on the neighborhood of tw -- as done in Version 2 -- has got nothing to do with the problem confronting us which is to determine how robust control unit s is with respect to the true value of t (which is subject to severe uncertainty). Here tw is not a nominal value, or a reference point but, a wild guess at the true value of t.
So, the lesson for Info-Gap users is that for all the bombastic rhetoric in the Info-Gap literature, Info-Gap decision theory does not provide a methodology for robust decision-making in the face of severe uncertainty. The methodology that it provides for this purpose does no more than measure safe deviations from a wild guess.
Info-Gap decision theory does not tackle the severity of the uncertainty it is supposed to manage, it ... ignores it.
Put another way, Info-Gap decision theory makes it its business to determine the "safe" deviations from the estimate û, whereas decision-making under severe uncertainty enjoins tackling the gap between the estimate û and the true value u*. This, of course, is the reason for my labeling Info-Gap decision theory a voodoo decision theory (see FAQ-6).
FAQ-73:Can you give a complete example illustrating the working of an info-gap model?
Answer-73: Certainly. The following example which is taken from my paper Sniedovich (2007) is based on an example outlined in (Ben-Haim 2006, pp. 70-74).
Example: Investment Portfolio
You have $Q to spare, so you consider a 10-year investment portfolio consisting of $n possible options (securities). The future values of these securities after 10 years are unknown as they are subject to severe uncertainty. The question is then: given the uncertainty, what is the best investment strategy?
To give readers who have not encountered this problem before a fuller appreciation of the difficulties presented by it, let us first consider a much simpler version thereof. Let us pretend that the future values of the securities are known. In this case we can state the problem under consideration as follows:
Remarks
Info-Gap decision theory does not address the important practical question of how such optimization problems are solved.
In our particular case, the optimization problem is a composite concave programming problem that can be solved efficiently by parametric quadratic programming methods (see Churilov et al 2004).
Since the value of r* is "subjective", in practice it might be necessary to solve the problem for a range of values of r* to determine the acceptable tradeoff between r* and the robustness α(û).
More importantly, because no serious thought is given to the fact that -- under the assumed conditions of severe uncertainty -- the estimate û is a wild guess, no serious thought is given to the requirements dictated by this fact. This means that the Info-Gap analysis is utterly oblivious to the fact that it is imperative to conduct an extensive sensitivity analysis with respect to the estimate û.
Similar criticism is induced by the "localness" of Info-Gap's robustness analysis. Given that the "best" investment yielded by this robustness analysis is best "locally", it is imperative to investigate how well the identified "best" investment performs with respect to the entire region of uncertainty of the parameter u.
It is important to take note that if you disregard the blunders that are typical to Info-Gap's methodology in its broad outlines, Info-Gap's proposed treatment of the problem under consideration here is almost a "carbon copy" of the treatment proposed by Markowitz's "classical" portfolio optimization method (circa 1952). Recall that this methodology calls for a Pareto tradeoff between xTû and xTWx, where the objective is to make xTû as large as possible and xTWx as small as possible.
Observe, however, that Markowitz's famous methodology does not assume that the estimate û is a wild guess. Indeed, this methodology is based on a probabilistic model where uj is treated as a random variable and ûj denotes the expected value of uj that is stipulated by the assumed probability distribution of û. Similarly, W denotes the covariance matrix associated with the random variables uj, j=1,...,n.
It should therefore be clear that my discussion of Info-gap's treatment of the problem is for illustration only and carries no endorsement whatsoever of any of its elements.
FAQ-74: Does Info-Gap robustness represent likelihood of safe performance?
Answer-74: Of course it does not! How can it?!
When all the rhetoric is stripped away, the Info-Gap methodology boils down to a non-probabilistic, likelihood-free model of robustness that -- according to its founder -- is designed specifically for decision-making under severe uncertainty. Granted, the theory does not offer a formal definition of severe uncertainty. Still, the underlying understanding is that the Info-Gap model gives expression to situations where the estimate of a parameter of interest is a poor indication of the true value and is likely to be substantially wrong.
In other words, the underlying idea is that the estimate is no more than a guess -- perhaps a wild guess -- of the true value of the parameter of interest. Some Info-Gap scholars even consider situations where the estimate can be based on gut feeling and rumors.
The poor quality of the estimate û explains why the horizon of uncertainty, α, of Info-Gap's nested regions of uncertainty, U(α,û), α≥ 0, is unbounded above.
In this framework, the robustness of decision d is, by definition, the largest value of α, call it α(d,û), such that the performance requirement is satisfied by d at every point u in the region of uncertainty U(α(d,û),û):
α(d,û):= max {α≥0: r(d,u) ≥ r*, ∀u∈U(α,û)}
The following is a schematic representation of the result generated by Info-Gap's robustness analysis for decision d, where the red area around the estimate û represents the largest safe region around the estimate associated with this decision
û
Safe sub-region
<-----------------
Complete region of uncertainty
----------------->
Now, key to this analysis and the results generated by it is that pre-analysis as well as post-analysis, the true value of u can be anywhere in the complete region of uncertainty U, including the No Man's Land.
Of course, this result is fully concordant with the thinking underlying Info-Gap decision theory. For as already pointed out in FAQ-37, the theory makes no assumption whatsoever regaring the likely location of the true value of u. To reiterate, nowhere is it assumed that the true value of u is more likely to be in the neighborhood of the estimate û than in any other neighborhood in the complete region of uncertainty U.
In short, Info-Gap's uncertainty model is not only non-probabilistic, it is also likelihood-free and membership-free (Info-Gap's uncertainty model is not a fuzzy-set model).
This means, of course, that Info-Gap's robustness model does not admit of any talk of "likelihood". And the immediate consequence of this key point is that Info-Gap robustness does not -- nor can it -- represent the likelihood of "successful" events such as "Decision d satisfies the performance requirement".
Indeed, the claim that Info-Gap robustness represents the likelihood of "safe performance" flies in the face of Ben-Haim's long standing position on this matter. This position even predates the formulation of Info-Gap's robustness model: It goes back to the use of convex models to represent uncertainty.
And to illustrate, consider this (emphasis is mine):
While uncertainty in the shell shapes is fundamental to this analysis, there is no likelihood information, either in the formulation of the convex model or in the concept of reliability
.........
........
However, unlike in a probabilistic analysis, r has no connotation of likelihood. We have no rigorous basis for evaluating how likely failure may be; we simply lack the information, and to make a judgement would be deceptive and could be dangerous. There may definitely be a likelihood of failure associated with any given radial tolerance. However, the available information does not allow one to assess this likelihood with any reasonable accuracy.
Ben-Haim (1994, p. 152)
and this:
Classical reliability theory is thus based on the mathematical theory of probability, and depends on knowledge of probability density functions of the uncertain quantities. However, in the present situation we cannot apply this quantification of reliability because our information is much too scanty to verify a probabilistic model. The info-gap model tells us how the unknown seismic loads cluster and expand with increasing uncertainty, but it tells us nothing about their likelihoods.
Ben-Haim (1999, p. 1108)
and this:
In any case, an info-gap model of uncertainty is less informative than an probabilistic model (so its use is motivated by severe uncertainty) since it entails no information about likelihood or frequency of occurrence of u-vectors.
Ben-Haim (2001a, p. 5)
and this:
In info-gap set models of uncertainty we concentrate on cluster-thinking rather than on recurrence or likelihood. Given a particular quantum of information, we ask: what is the cloud of possibilities consistent with this information? How does this cloud shrink, expand and shift as our information changes? What is the gap between what is known and what could be known. We have no recurrence information, and we can make no heuristic or lexical judgments of likelihood.
Ben-Haim (2006, p. 18)
That said, the following question immediately springs to mind, and would no doubt be raised by anyone -- expert in the field or novice:
If, as so emphaticaly argued by Ben-Haim himself, it cannot be posited that the true value of u is more likely to be in the neighborhood of the estimate û than in other neighborhoods of the complete region of uncertainty U, what is the sense of a-priori fixing on this specific neighborhood and conducting the robustness analysis exclusively around û?
This inevitable question explains why I dub Info-Gap decision theory a "voodoo decision theory".
In any event, my point is that Info-Gap users/scholars are thoroughly careless in their depiction of the robustness yielded by Info-Gap. Indeed, not only Info-Gap scholars, even Ben-Haim himself, seems unable to resist the temptation to impute "likelihood" to Info-Gap's robustness (emphasis is mine):
Information-gap (henceforth termed `info-gap') theory was invented to assist decision-making when there are substantial knowledge gaps and when probabilistic models of uncertainty are unreliable (Ben-Haim 2006). In general terms, info-gap theory seeks decisions that are most likely to achieve a minimally acceptable (satisfactory) outcome in the face of uncertainty, termed robust satisficing. It provides a platform for comprehensive sensitivity analysis relevant to a decision.
Burgman, Wintle, Thompson, Moilanen, Runge, and Ben-Haim (2008, p. 8)
This, of course, is utterly erroneous.
But more than this:
How is it that a methodology that in 2006 could not tell us anything about the likelihood of severely uncertain events, is used in 2009 to seek decisions that are most likely to perform well under high uncertainty?
Clearly, there is no way to justify this position!
Because, as the above quoted statements from Ben-Haim (1994, 1999, 2001a, 2006) categorically contend, Info-Gap decision theory " ... can make no heuristic or lexical judgments of likelihood ..."
And more than this, by its very nature, Info-Gap's robustness analysis is local. This means that this analysis, cannot possibly tell us anything about the likelihood of events that occur outside the largest region of uncertainty around the estimate that it considers "safe". In other words, Info-Gap's robustness analysis cannot tell us anything about the "likelihood" of events in its -- typically vast -- No-Man's Land:
û
Safe sub-region
<-----------------
Complete region of uncertainty
----------------->
And yet, despite all this, and despite Ben-Haim's (1994, 1999, 2001a, 2006) clear warnings, Info-Gap scholars -- including Ben-Haim himself -- now argue that their non-probabilistic, likelihood-free models can be used to draw very strong conclusions regarding the likelihood of highly uncertain events!
If this is not Voodoo decision-making, what is?!
For, isn't it clear that the following two statements about the nature of Info-Gap decision theory are contradictory:
Info-Gap is a non-probabilistic, likelihood-free theory.
Info-Gap can evaluate and compare the likelihood of severely uncertain events.
Unfortunately, such zigzags are not unusual in Info-Gap.
As shown elsewhere in this compilation, the preferred practice in Info-gap is to extend an error rather than admit to a mistake.
Having said all that, the following ought to be noted. Of course it is possible to construct simple, specially contrived cases where Info-Gap's robustness of a decision would be a proxy for the "probability of success", namely the probability that the decision satisfies the performance requirement (eg. Ben-Haim 2006, pp. 283-284).
But this in no way serves as a justification for generalized statements about Info-Gap's robustness, so that it is totally erroneous to claim that
In general terms, info-gap theory seeks decisions that are most likely to achieve a minimally acceptable (satisfactory) outcome in the face of uncertainty, termed robust satisficing.
Indeed, such claims give an utterly distorted view of what Info-Gap is all about and in particular of its robustness model. To be precise, statements such as this give a totally incorrect account of Info-Gap's definition of robustness:
α(d,û):= max {α≥0: r(d,u) ≥ r*, ∀u∈U(α,û)}
û
Safe Sub-region
<-----------------
Complete region of uncertainty
----------------->
So the bottom line is this:
Info-Gap robustness model is a non-probabilistic model (see FAQ-37).
Info-Gap robustness model is a likelihood-free model (see FAQ-37).
Info-Gap robustness therefore cannot -- in general (Unless some additional simplifying assumptions are made. These assumptions would imply that the uncertainty under consideration is not severe.) -- be a proxy for the likelihood of events such as "success" or "failure" of a performance requirement.
Info-Gap's robustness model is a simple Maximin model (FAQ-18).
Info-Gap's robustness analysis is local (see FAQ-13).
Info-Gap's robustness analysis has the property that it is chronically invariant to the size of the complete region of uncertainty (see FAQ-15 | FAQ-17).
Info-Gap's robustness analysis is unsuitable for the treatment of severe uncertainty because it ignores the severity of the uncertainty.
Claims such as: Info-Gap decision theory " ... seeks decisions that are most likely to achieve a minimally acceptable (satisfactory) outcome in the face of uncertainty ..." are without any foundation.
FAQ-75: What are the ramifications of the argument that Info-Gap robustness does not represent likelihood of events?
Answer-75: The argument showing that Info-Gap robustness does not represent likelihood of events brings into full view the fundamental flaw in Info-Gap decision theory: the flaw exposing it for the voodoo decision theory it is. It also brings out the muddled reasoning behind a misinterpretation of Info-Gap robustness that is common in the Info-Gap literature.
To explain this point, let us consider the simple case where the complete region of uncertainty is the positive segment of the real line. That is, assume that U=(0,∞). This means that the true value of u, call it u*, is equal to some non-negative number.
Since the value of u* is subject to severe uncertainty, all we know is that it is somewhere on U. That is, given that the uncertainty is severe, we have not the slightest inkling whether u* is more or less likely to be for instance in [100,200] rather than in [600,700], or whether it is more or less likely that u* ≤ 200 than u*≥ 200. We simply have no clue.
What Info-Gap users/scholars fail to appreciate is that the imposition of Info-Gap's ad hoc uncertainty model on U, does not make the slightest dent, not even by one iota, in the severity of the uncertainty. And to illustrate, let û=500 and
U(α,û):={u≥0: |u-û| ≤ α} , α≥ 0
The uncertainty in the true value of u has not changed even in the slightest, despite the imposition of these regions of uncertainty on U. We remain as ignorant as before as to whether u* is more or less likely to be in [100,200] than in [600,700], or whether it is more/less likely that u* ≤ 200 than u*≥ 200. We simply do not know.
The point here is that the choice of u*=500 as a wild guess of u* in no way indicates that, all of a sudden, we have come to know that u* is more/less likely to be in the neighborhood of u*=500.
Consequently, the robustness of a decision a la Info-Gap, namely
α(d,û):= max {α≥ 0: r* ≤ r(d,u), ∀ u∈ U(α,û)} , d∈ D
has got nothing to do with the "likelihood" that d will satisfy the performance constraint r*≤ r(d,u).
That is, the fact that α(d'',û) < α(d',û) does not imply that decision d' is more/less likely to satisfy the performance constraint. All we can say is that
α(d',û) is the largest value of α such that r*≤ r(d',u), ∀ u ∈ U(α,û)
α(d'',û) is the largest value of α such that r*≤ r(d'',u), ∀ u ∈ U(α,û)
observing that the last statement is a consequence of the nesting property of Info-Gap's regions of uncertainty.
As far as "likelihood" goes, all we can say is that decision d' is certain to satisfy the performance constraint if the true value of u is in U(α(d',û),û) and that d'' is certain to satisfy the performance constraint if the true value of u is in U(α(d'',û),û).
But we are in no position whatsoever to contend anything about how likely this will be.
The picture is this:
û
Safe sub-region
<-----------------
Complete region of uncertainty
----------------->
But, this of course is hardly surprising as Info-Gap's robustness model:
α(d,û):= max {α≥0: r(d,u) ≥ r*, ∀u∈U(α,û)}
is non-probabilistic and likelihood-free.
And to illustrate, consider this (emphasis is mine):
While uncertainty in the shell shapes is fundamental to this analysis, there is no likelihood information, either in the formulation of the convex model or in the concept of reliability
.........
........
However, unlike in a probabilistic analysis, r has no connotation of likelihood. We have no rigorous basis for evaluating how likely failure may be; we simply lack the information, and to make a judgement would be deceptive and could be dangerous. There may definitely be a likelihood of failure associated with any given radial tolerance. However, the available information does not allow one to assess this likelihood with any reasonable accuracy.
Ben-Haim (1994, p. 152)
and this:
Classical reliability theory is thus based on the mathematical theory of probability, and depends on knowledge of probability density functions of the uncertain quantities. However, in the present situation we cannot apply this quantification of reliability because our information is much too scanty to verify a probabilistic model. The info-gap model tells us how the unknown seismic loads cluster and expand with increasing uncertainty, but it tells us nothing about their likelihoods.
Ben-Haim (1999, p. 1108)
and this:
In any case, an info-gap model of uncertainty is less informative than an probabilistic model (so its use is motivated by severe uncertainty) since it entails no information about likelihood or frequency of occurrence of u-vectors.
Ben-Haim (2001a, p. 5)
and this:
In info-gap set models of uncertainty we concentrate on cluster-thinking rather than on recurrence or likelihood. Given a particular quantum of information, we ask: what is the cloud of possibilities consistent with this information? How does this cloud shrink, expand and shift as our information changes? What is the gap between what is known and what could be known. We have no recurrence information, and we can make no heuristic or lexical judgments of likelihood.
Ben-Haim (2006, p. 18)
The question requiring an answer in the first instance is of course the following:
Given that we have not the slightest clue as to whether the true value of u is more likely to be in the neighborhood of the estimate û, what is the rationale for singling out this particular neighborhood out of the complete region of uncertainty and proceeding to confine the robustness analysis to this neighborhood?
This, of course, is the reason for my dubbing Info-Gap a voodoo decision theory: even though there is no reason to believe that the true value of u is, or is likely to be, in the neighborhood of the wild guess û, Info-Gap fixes its robustness analysis in this neighborhood without bothering to check how decisions fare elsewhere in the complete region of uncertainty.
But more bewildering is the fact that now Ben-Haim attributes to his non-probabilistic, likelihood-free robustness model the capability to evaluate/compare the likelihood of events such as whether the performance requirement is satisfied (emphasis is mine):
Information-gap (henceforth termed `info-gap') theory was invented to assist decision-making when there are substantial knowledge gaps and when probabilistic models of uncertainty are unreliable (Ben-Haim 2006). In general terms, info-gap theory seeks decisions that are most likely to achieve a minimally acceptable (satisfactory) outcome in the face of uncertainty, termed robust satisficing. It provides a platform for comprehensive sensitivity analysis relevant to a decision.
Burgman, Wintle, Thompson, Moilanen, Runge, and Ben-Haim (2008, p. 8)
The only way that one can claim validity to this statement is to show, or in the very least make the explicit assumption, that the true value of u is likely to be in the neighborhood of the estimate û. But can such an assumption even be contemplated given that the true value of u is subject to severe uncertainty?
I must conclude, therefore, that either this statement is one of those unfortunate slips, or that Info-Gap no longer claims to be a theory dealing with severe uncertainty, in which case it would be necessary to change, among other things, the title of Ben-Haim's (2006) book.
If, however, this claim is upheld, then it would be totally in line with the established practice in Info-Gap, where — as my experience over the past five years has shown — extending an error is preferred to admitting to a mistake.
The important point to note here, incredible though it is, is that this indeed is how the estimate û is grasped and interpreted -- of course, misinterpret -- by Info-Gap scholars/users. So, the real issue here is that they seem unperturbed by the idea that a local analysis in the neighborhood of a wild guess of a parameter of interest can yield robustness against severe uncertainty
û
Safe sub-region
<-----------------
Complete region of uncertainty
----------------->
This is what is so troubling about this matter!
FAQ-76: Have there been any attempts to correct the fundamental flaws in Info-Gap decision theory?
Answer-76: This seems to be the case.
Before I proceed to discuss this question I need to point out that when I refer to attempts at correcting flaws in Info-Gap decision theory, I do not mean to suggest that one would find in the Info-Gap literature expressions such as:
" ... In this discussion we address the following flaw in Info-Gap decision theory ..."
" ... Here is the remedy we propose for this flaw ..."
This is not the way things are done in the Info-Gap literature.
The established practice in the Info-Gap literature, and this has been the case right from its launch, is to engage in rhetoric.
Hence, statements openly acknowledging the existence of flaws in the theory accompanied by arguments outlining proposed corrections should not be expected. Rather, one should expect to find dissertations consisting of verbiage that inadvertently alludes to flaws, accompanied by semantic quick fixes that superficially attempt to dress up the fundamental flaws without really dealing with them in a serious manner.
These lame, counter-productive attempts are reminiscent of the following familiar formula:
Q: How do you catch a blue kangaroo?
A: With a blue kangaroo trap.
Q: How do you catch a green Kangaroo?
A: Paint it blue and catch it with the blue kangaroo trap.
In other words, they offer no more than a superficial "paint job".
But, as we know only too well, such "miracle cures" can offer no remedy at all.
For, as we shall see, not only do these remedies fall short of addressing Info-Gap's endemic flaws, all they actually manage to do is to exacerbate an already sorry state-of-affairs.
As things stand now, it seems that a number of Info-Gap scholars have taken note of my criticism of Info-Gap decision theory to the effect that they have deemed it necessary to take certain measures that, they apparently believe, will blunt its bite.
So before we can go into this matter, let us first recall that the two main points of my criticism of Info-Gap are that:
Info-Gap's robustness model is not novel -- it is a simple Maximin model (circa 1940).
Info-Gap decision theory is unsuitable for decision-making under severe uncertainty.
Also, recall that Info-Gap's robustness model is formulated as follows:
α(d,û):= max {α≥ 0: r* ≤ r(d,u), ∀ u∈ U(α,û)} , d∈ D
It is also important to keep in mind the schematic representation of the result generated by Info-Gap's robustness analysis for decision d, where the white area around the estimate û represents the largest safe region around the estimate associated with this decision.
û
Safe sub-region
<-----------------
Complete region of uncertainty
----------------->
Let us now examine, in fact revisit, the issues that are raised by the above two points and let us see how instead of dealing with these issues directly, Info-Gap scholars go for the evasive counter-productive quick fix.
The Maximin Saga:
The flaw:
Info-Gap users/scholars have been operating under the mistaken belief that Info-Gap's robustness model is a distinctive, novel, revolutionary non-probabilistic approach to decision-making under uncertainty. This is how this model has been described, in fact hailed, by Info-Gap scholars and this is how its use has to-date been justified, indeed promoted.
As I have shown on numerous occasions, the fact is that Info-Gap's robustness model is a simple instance of none other than Wald's Maximin model (circa 1940) -- the most famous non-probabilistic model for decision-making under severe uncertainty.
Attempted fix:
Ben-Haim -- the Founder of Info-Gap -- continues to deny that Info-Gap's robustness model is a Maximin model. And to support this claim he persistently revisits a number of woefully mistaken arguments that presumably show that Info-Gap robustness model is not a Mximin model (see FAQ-20).
Other Info-Gap scholars simply avoid discussing this issue altogether in their writings. That is, they remain silent on the Info-Gap/Maximin connection thus betraying their scholarly duty to answer to criticism that refutes their key contention about a theory that they promote. Worse, given that without challenging this criticism they continue to refer to Info-Gap as a new or independent (non-derivative) method that they propose as a tool in decision-making, they continue to perpetuate a totally wrong view of this flawed method.
In a word, the "quick fix'' here is simply to ... pretend that there is no elephant in the room!
Severe Uncertainty:
The Flaw:
Info-Gap decision theory -- as described by its founder -- was designed expressly for the purpose of managing decision under severe uncertainty. In other words, Severe Uncertainty is Info-gap's raison d'etre. This is how it has been hailed and promoted ever since its launch and this is how its use has been justified by its users.
Of course, the fact of the matter is -- as I have shown time and again -- that Info-Gap decision theory is an utter failure at the management of severe uncertainty. Indeed, the reasons for Info-Gap's failure to deal with severe uncertainty are so obvious and compelling that they can be easily explained to anyone -- professional or otherwise (see FAQ-15 -- FAQ-17).
Attempted fix:
To-date (February 6, 2009) I have discovered two radically different types of "remedies'' for this flaw:
Semantic remedy.
Self-defeating remedy.
The Semantic remedy is simplicity itself. The terms "severe uncertainty" and/or "Knightian uncertainty" that until now have been de rigueur in the Info-gap literature to describe the type of uncertainty under consideration, are dropped and replaced by new terms such as "substantial uncertainty", "highly uncertain" and so on.
Of course, the question arising is what exactly is accomplished by this shift in jargon? After all, it is Info-Gap business as usual in these publications as well. The same flawed robustness model is used to treat the same old problems (subject to severe uncertainty) by means of the same old (Maximin) analysis.
In contrast, the Self-defeating remedy retains the claim that Info-Gap decision theory indeed tackles severe uncertainty. Hence, its attempt to deal with the criticism that Info-Gap's prescription for severe uncertainty is fundamentally flawed is to introduce an assumption that will justify the logic behind Info-Gap's local robustness analysis.
I refer to this attempt as "Self-defeating" because the assumption that it posits completely destroys the foundation of Info-Gap decision theory. It ascribes Info-Gap's non-probabilistic, likelihood-free uncertainty model "secret powers" capable of representing a presumably "dormant'' powerful "likelihood" property.
Specifically, this assumption makes the following innovation about the severe uncertainty expressed by Info-Gap's uncertainty model:
The estimate û is the most likely true value of u.
The likelihood that u' is the true value of u decreases as u' deviates from the estimate û.
For instance, consider the following specific formulation of such an assumption:
An assumption remains that values of u become increasingly unlikely as they diverge from û.
Hall and Harvey (2009, p. 2)
Briefly, this assumption fails on two counts so that more than rectifying the fundamental flaw, it exacerbates it:
This assumption is clearly unable to correct the flaw.
This assumption does not entail that the true value of u is in the immediate neighborhood of û. In fact, this assumption does not even entail that the true value of u is very likely to be in the immediate neighborhood of û. But more than this, it is very easy to construct examples where this assumption is satisfied, yet the true value of u is very unlikely to be in the immediate neighborhood of û.
This assumption contradicts Ben-Haim's depiction of Info-Gap's uncertainty model.
Recall that Ben-Haim -- the Founder of Info-Gap -- is adamant that Info-Gap's uncertainty model does not represent likelihood. For instance (emphasis is mine):
In info-gap set models of uncertainty we concentrate on cluster-thinking rather than on recurrence or likelihood. Given a particular quantum of information, we ask: what is the cloud of possibilities consistent with this information? How does this cloud shrink, expand and shift as our information changes? What is the gap between what is known and what could be known. We have no recurrence information, and we can make no heuristic or lexical judgments of likelihood.
Ben-Haim (2006, p. 18)
That said, my response to these attempted remedies is as follow:
Maximin Saga
To be sure, the revelation that Info-Gap's robustness model is no more than a run-of-the-mill Maximin model is a source of embarrassment to all those who have been promoting Info-Gap as a distinctive, novel, revolutionary methodology for decision-making under uncertainty. But now that this fact is widely known and well understood, what is the point of maintaining the silence on this central point?
What good does it do to the advancement of science in general and to decision theory in particular?
What must be done now is the precise opposite.
It is incumbent on Info-Gap scholars to state publicly that the theory that was once introduced and promoted as being distinctive, new and revolutionary is in fact an instance of the well established, famous methodology that is universally known as Maximin.
Ben-Haim's continued futile attempts to show that Info-Gap's robustness model is not a Maximin model are misguided, counter-productive and in fact embarrassing.
Severe Uncertainty
Expunging "severe" from "severe uncertainty" in the Info-Gap lexicon will have no affect whatsoever on the fact that the uncertainty represented by Info-Gap's robustness model is, and remains, severe. So what is to be gained from this tinkering with the language?
Technically, the only way to fix Info-Gap's robustness model is to postulate the following:
Assumption:
The estimate û is good and reliable, namely the true value of u is in the immediate neighborhood of û.
But, if this assumption were to hold, then it would be grossly inconsistent to maintain that the uncertainty in the true value of u is "substantial", or "high", in other word that the situation under consideration is "substantially uncertain" or "quite uncertain", or "highly uncertain" or whatever you want to call it.
I shall enlarge on this issue in due course to reflect new developments on this front. For the time being, all I do is reiterate that:
The flaws in Info-Gap decision theory are deep-rooted which means that they cannot be explained away semantically.
Not only is the silence on the fact that Info-Gap's robustness model is a simple Maximin model utterly unscholarly, it also constitiutes a disservice to readers of the Info-Gap literature who are thus left uninformed about the huge knowledge-base associated with the Maximin model.
And to sum it all up, my reaction to the futile attempts of Info-Gap adherents to deal with its fundamental flaws can be described as follows:
The more things are changed, the more they stay the same: flawed!
The question is then how long before a real change takes place?
For the record, here is the time-stamp: 09:03, February 6, 2009, Melbourne time.
FAQ-77: What is the difference between "substantial uncertainty", "high uncertainty" and "severe uncertainty"?
Answer-77: Can one seriously suggest that there is any difference?!
As explained in FAQ-75, the latest trend in the Info-Gap literature has been the introduction of new terms such as "substantial uncertainty", "high uncertainty" and the like. These apparently have been introduced in lieu of the more traditional "severe uncertainty" that to-date has been the ruling term in the Info-Gap literature to describe the uncertainty under consideration.
I imagine that this change in jargon has come in response to my proof (see FAQ-15 -- FAQ-17) that Info-Gap decision theory is not capable of dealing with severe uncertainty.
In other words, I show that Info-Gap is in principle unable to deal with severe uncertainty, so what do we get in response? The term "severe" is dropped to be replaced by "substantial" or "high". Clearly, the thinking behind this seems to be that by dropping the term "severe" one effectively liberates Info-Gap's robustness model from my criticism. So, considering this quick fix, it is important to be clear on what it would really take to accomplish the task of fixing Info-gap decision theory.
The first point to note is that for all this tinkering with the language, the definition of robustness in recent publications remains precisely the same as that formulated in all previous Info-Gap publications. That is, robustness according to Info-Gap decision theory was and remains as follows:
α(d,û):= max {α≥0: r(d,u) ≥ r*, ∀u∈U(α,û)}
û
Safe sub-region
<-----------------
Complete region of uncertainty
----------------->
Of course, as I have been arguing all along, this is precisely where the trouble lies. For, to make a case for this definition, or in the very least show that it is sensible, one must show that the true value of u is in the immediate neighborhood of û.
But to adopt such a position would run counter to Ben-Haim's own position on the meaning of severe uncertainty. For -- according to Ben-Haim -- severe uncertainty implies that the estimate û is poor and likely to be substantially wrong, the implication being that under severe uncertainty there is no guarantee that the true value of u is in the immediate neighborhood of û.
So, my criticism has been that given this understanding of severe uncertainty, prescribing a robustness analysis of the kind prescribed by Info-Gap decision theory amount to engaging in voodoo decision theory.
There is no other way to correct this obvious flaw but to posit that Info-Gap's uncertainty model is based on the following:
Assumption 1: The estimate û is good and reliable, namely the true value of u is in the immediate neighborhood of û.
In other words, no amount of tinkering with the term "severe uncertainty" can make one iota of difference. In the context of Info-Gap's robustness model "substantial uncertainty", "high uncertainty", or "severe uncertainty" connote precisely the same condition regarding the estimate û. To repeat: the estimate û is poor and likely to be substantially wrong, the implication being that under severe uncertainty there is no guarantee that the true value of u is in the immediate neighborhood of û.
Of course, in practice it may well prove necessary to invoke a weaker version of this assumption as follows:
Assumption 2: The estimate û is good and reliable, namely it is "very likely" that the true value of u is in the immediate neighborhood of û.
But once an Info-Gap model is premised on this assumption, one must be careful how the uncertainty under consideration is described. It will be very difficult to explain a situation where:
Assumption 2 is satisfied.
The uncertainty in the true value of u is understood to be substantial, high, or severe.
In short, the trouble with Info-Gap decision theory is not that it is dubbed a theory for decision-making under severe uncertainty, the trouble is that it does not measure up to this description.
What a mess!
FAQ-78: Why is it erroneous to impute "likelihood" to Info-Gap's robustness?
Answer-78: As attested by its founder, Info-Gap decision theory was designed as a non-probabilistic, likelihood-free -- to which I should add, membership-free -- theory. The immediate implication of this is that any talk of "likelihood" in the Info-Gap context runs counter to its conceptual foundation, indeed its justification.
In other words, the attribution of "likelihood" to any core element of Info-Gap decision theory, be it the estimate, the robustness result, or whatever, not only introduces a radical change in its foundation, it effectively results in a new theory that is utterly different from the original one.
To be specific, the mere fact that to model the uncertainty under consideration, Info-Gap defines the regions of uncertainty U(α,û),α≥ 0, does not in any way shape or form make us the wiser as to what values of u are more/less likely than others. To repeat, defining U(α,û),α≥ 0, as such, gives no indication whatsoever what values of u are more/less likely than others. Indeed, as attested by its founder, Info-Gap decision theory was designed specifically for situation where -- for whatever reason -- such a quantification of uncertainty cannot be contemplated because it is impossible.
Of course, this is not to say that it is impossible to develop a brand new theory that defines regions of uncertainty similar to those defined by Info-Gap, but in whose context the likelihood of events associated with the unknown parameter u is quantified. It must be realized, however, that such a new theory will be quite different from Info-Gap. Because, to have any merit, indeed to be useful, this new theory would necessarily have to quantify the notion "likelihood" and to re-define robustness accordingly.
Be that as it may, to illustrate the issue under consideration, consider the following attempt to impute likelihood to Info-Gap's uncertainty model:
An assumption remains that values of u become increasingly unlikely as they diverge from û.
Hall and Harvey (2009, p.2)
The first question requiring an immediate reply is obvious:
Why do we have to make this assumption about the conventional likelihood-free Info-Gap model?
Why, for instance, is this assumption not made about the Info-Gap model described in Hall and Ben-Haim (2007)? Clearly this assumption is not made with regard to any model featured in the Info-Gap book (Ben-Haim, 2006) so, are we to postulate it now retrospectively?
These questions go to the heart of the issue raised in Hall and Harvey's (2009), but are not addressed there.
My reading of the situation is as follows.
This assumption was introduced by Hall and Harvey (2009) as an ad hoc attempt to circumvent or perhaps deflect my criticism of Info-gap's robustness model.
Its objective apparently is to explain and justify the logic behind Info-Gap's -- local -- definition of robustness. For, as you will recall, I have been arguing that if there is no reason to believe that the true value of u is in the neighborhood of û, what is the sense of singling out this neighborhood for analysis or in other words: Info-Gap's definition of robustness does not make much sense.
So, by virtue of this assumption Hall and Harvey (2009) apparently seek to explain and justify why Info-Gap's robustness is defined as the largest "safe" deviation from the estimate û.
But the irony here is that Hall and Harvey's (2009) assumption is not nearly as strong as they presumably imagine to provide a remedy for the flaw discussed above. To see why this is so observe that the fact that values of u become increasingly unlikely as they diverge from û in no way implies that the true value of u is very likely to be in the immediate neighborhood of the estimate û.
To illustrate, consider the case where the complete region of uncertainty is the real line, namely U= (-∞,∞). Also assume that û=0.
Now, suppose that unbeknownst to the decision maker, the "likelihood'' of the true value of u is determined probabilistically by the Normal distribution having mean μ=0 and variance σ2.
Then clearly, Hall and Harvey's (2009) assumption holds for any value of σ2. But for very large values of σ2 the likelihood that the true value of u is in the immediate neighborhood of û is relatively small, and can be made arbitrarily small by increasing the value of σ2.
This demonstrates that for Hall and Harvey's (2009) assumption to do the job, it must be strengthened significantly so as to imply that the true value of u is very likely to be in the immediate neighborhood of the estimate û.
But, once an assumption of this nature is incorporated in Info-Gap decision theory, then surely the uncertainty under consideration will no longer be severe and the entire Info-Gap empire will therefore collapse:
"... Info-gap theory is useful precisely in those situations where our best models and data are highly uncertain, especially when the horizon of uncertainty is unknown. In contrast, if we have good understanding of the system then we don't need info-gap theory, and can use probability theory or even completely deterministic models. It is when we face severe Knightian uncertainty that we need info-gap theory. ..."
Ben-Haim's (2007, p. 2)
In short, it is time for Info-Gap scholars to face reality and take a serious look at the obvious flaws afflicting the theory. It is impossible to mend the theory by sewing on patches. This only exposes it to harsher criticism.
FAQ-79: How is it that Info-Gap decision theory is so laconic about the estimate û?
Answer-79: This question brings out another serious methodological failing of Info-Gap.
The point is this. The estimate û constitutes the fulcrum of Info-Gap's uncertainty and robustness models. It is the core element around which revolves the robustness analysis which, according to Info-Gap's prescription, provides the basis for identifying (presumably) robust decisions. And yet, the theory has precious little to say about û.
It is remarkable that, in sharp contrast to the lengthy dissertations that are devoted to the "Knightian" uncertainty that Info-Gap (purportedly) takes on, not the slightest instruction is given to enlighten us on how the estimate û is determined. What qualities -- if any -- should it have? What requirements should it satisfy? And so on. All we know is that in the framework of Info-Gap decision theory one proceeds on the assumption that û is an estimate of the true value of u.
So, formally we give expression to this idea by stating that û is an element of U and that U(0,û)={û}. And since the regions of uncertainty are nested, it also follows that û∈U(α,û), ∀α≥ 0,in fact all the regions of uncertainty U(&alpha:,û),α≥ 0 are "centered" at û.
But the whole point here is that when applying the Info-Gap decision theory to a specific case, the entire exercise is conducted under conditions of severe uncertainty. So the really important question is: given that we are in the dark as to the true value of our parameter of interest, how do we go about determining its estimate, namely the value of û? Would we be able, or required, or whatever, to consult a list of considerations that will enable us to settle on a specific value of û?
And more than this. What if we do not have, or cannot come up with, an estimate of the true value of u? And what if we have more than one estimate of the true value of u, say an "interval" of possible (probable ?) values?
The phrase "best estimate" (sometimes "best guess") is used extensively in the Info-Gap literature to describe û. Of course, the question that immediately come to mind is: why should Info-Gap scholars and users think it necessary to designate û as the "best estimate"? Why doesn't the simple unqualified "estimate" suffice?
On this one can only speculate as nowhere in this literature would one find any discussion or argument setting out the justification for this Info-Gap terminology. The most likely explanation seems to be, though, that behind this is the tacit recognition that objections are certain to be raised against the inexcusable practice of treating a "poor", "questionable", "doubtful", "unreliable" estimate as though it were a "decent", "acceptable" even "reliable" estimate.
After all, Info-Gap's robustness model operates under conditions of severe uncertainty, so the value of û that is used in the analysis is a poor indication of the true value of u and is likely to be substantially wrong (Ben-Haim 2007, p. 2). Hence, to disarm (excpected) objections Info-gap users have taken to calling a "wild guess" a "best guess" and a "poor estimate" a "best estimate".
It should also be pointed out that appellations such as "best understanding" and "nominal value" are also being used in the literature to describe û.
The question of course is: in what sense is the value of û "best" to thus render it the contender that one would settle on? Are we to understand that there are other estimates available, but these cannot be deemed "best"? In this case what are the criteria that are used to decide which of the available estimates is "best"?
But as might be expected, all this is left unanswered.
One suspects that terms such as "best understanding" and "nominal value" are used in the Info-Gap literature to bestow an even greater legitimacy on the practice of treating û as though it were a fully fledged "acceptable" estimate.
It is important to keep in mind, therefore, that no amount of re-anointing û will alter the fact that our understanding -- under conditions of severe uncertainty -- is such that the value we assign û in the analysis is a poor indication of the true value of u and is likely to be substantially wrong. Ben-Haim (2007, p. 2) explains that the estimate can be a "wild guess" and other Info-Gap scholars indicate that it can be based on no more than "gut feeling" or "rumors".
And should you need it, here is a recipe for obtaining a best estimate:
Wet your index finger and put it in the air. Think of a number and double it.
FAQ-81: How is it that Info-Gap decision theory fails to prescribe a sensitivity analysis with respect to the estimate û?
Answer-81: This is one of those inexplicable facts about Info-Gap decision theory. For, given that the "severe uncertainty" obtains with respect to the true value of u, one would have expected that a sensitivity analysis with respect to its estimate û be made an integral part of the methodology.
So, the fact that Info-Gap decision theory fails to prescribe a sensitivity analysis with respect to the estimate û is further testimony to the flawed thinking informing it. Indeed, it is a testimony to the underlying failure to appreciate that a methodology that is aimed at tackling severe uncertainty but confines its robustness analysis to the neighborhood of a single (point) estimate of u, in effect ignores the severity of the uncertainty that it is supposed to manage.
Of course, such a sensitivity analysis must be part and parcel of any methodology with pretensions to be considered a paradigm for decision-making under severe uncertainty. The difficulty in the case of Info-Gap is though that although conceptually such an analysis is "straightforward" -- vary the value of û and check how the solution changes -- its design and implementation within the framework of Info-Gap decision theory is not straightforward at all.
In particular, such an analysis will require that we determine the "best" decision from among those generated by changing the value of the estimate û. But, given the severe uncertainty in the true value of u, how would we do this?
For instance, suppose that our sensitivity analysis with respect to û consists of solving the problem for four different values of û, call them û(1), û(2), û(3), û(4), whereupon we obtain the following optimal decisions, respectively:
d(1)= Go North!
d(2)= Go South!
d(3)= Go East!
d(4)= Go West!
Where do we go, then?
Hence the following suggestion.
Given that an envisaged sensitivity analysis with respect to û would require varying the value of û, it would be simpler to evaluate the performance function r on some grid superimposed on the complete uncertainty region U and thus save the trouble of evaluating the robustness of decisions for each of the values of the estimate û generated by the sensitivity analysis.
In short, if one envisions a sensitivity analysis with respect to the value of û, it would be much simpler to conduct the sensitivity analysis with respect to u itself?! (see FAQ-45 for a different perspective on this issue).
FAQ-82:Is info-Gap's measure of robustness a reinvention of the good old "stability radius"?
Answer-82: Of course it is!
The origins of the concept Radius of Stability apparently go back to the 1960s, to discussions on stability in numerical analysis (Wilf 1960, Milne and and Raynolds 1962). Thus, in Milne and Raynolds (1962, p. 67) we read the following:
It is convenient to use the term "radius of stability of a formula" for the radius of the largest circle with center at the origin in the s-plane inside which the formula remains stable.
Note that in the case of Info-Gap decision theory the "formula" is the performance constraint r(d,p) ≤ r*. In short, Info-Gap's robustness model is a radius of stability model where the stability of the system is determined by the performance requirement r(d,p) ≤ r*.
In any case, today the concept "radius of stability" plays an important role in many fields such as applied mathematics, optimization theory, and control theory.
For instance, as indicated by Paice and Wirth (1998, p. 289):
Robustness analysis has played a prominent role in the theory of linear systems. In particular the state-state approach via stability radii has received considerable attention, see [HP2], [HP3], and references therein. In this approach a perturbation structure is defined for a realization of the system, and the robustness of the system is identified with the norm of the smallest destabilizing perturbation. In recent years there has been a great deal of work done on extending these results to more general perturbation classes, see, for example, the survey paper [PD], and for recent results on stability radii with respect to real perturbations ...
In the first edition of the Encyclopedia of Optimization, Zlobec (2001) describes the "radius of stability" as follows:
The radius of the largest ball centered at θ*, with the property that the model is stable at its every interior point θ, is the radius of stability at θ*, e.g, [69]. It is a measure of how much the system can be uniformly strained from θ before it starts breaking down.
First, the math-free picture.
Consider a system that can be in either one of two states: a stable state or an unstable state, depending on the value of some parameter p. We also say that p is stable if the state associated with it is stable and that p is unstable if the state associated with it is unstable. Let P denote the set of all possible values of p, and let the "stable/unstabe" partition of P be:
S = set of stable values of p. We call it the region of stability of P.
I = set of unstable value of p. We call it the region of instability of P.
Now, assume that our objective is to determine the stability of the system with respect to small perturbations in a given nominal value of p, call it p'. In this case, the question that we would ask ourselves would be as follows:
How far can we move away from the nominal point p' (under the worst-case scenario) without leaving the region of stability S?
The "worst-case scenario" clause determines the "direction" of the perturbations in the value of p': we move away from p' in the worst direction. Note that the worst direction depends on the distance from p'. The following picture illustrates the simple concept behind this fundamental question.
Consider the largest circle centered at p' in this picture. Since some points in the circle are unstable, and since under the worst-case scenario the deviation proceeds from p' to points on the boundary of the circle, it follows that, at some point, the deviation will exit the region of stability. This means then that the largest "safe" deviation from p' under the worst-case scenario is equal to the radius of the circle centered at p' that is nearest to the boundary of the region of stability. And this is equivalent to saying that, under the worst-case scenario, any circle that is contained in the region of stability S is "safe".
So generalizing this idea from "circles" to high-dimensional "balls", we obtain:
The radius of stability of the system represented by (P,S,I) with respect to the nominal value p' is the radius of the largest "ball" centered at p' that is contained in the stability region S.
The following picture illustrates the clear equivalence of "Info-Gap robustness" and "stability radius":
In short, for all the spin and rhetoric, hailing Info-Gap's local measure of robustness as new and radically different, the fact of the matter is that this measure is none other than the "old warhorse" known universally as stability radius.
And as pointed out above, what is lamentable about this state-of-affairs is not only the fact that Info-Gap scholars fail to see (or ignore) this equivalence, but also that those who should know better, continue to promote this theory from the pages of professional journals. See my discussion on Info-Gap Economics.
Math corner.
There are many ways to formally define the stability radius of a system. For our purposes it is convenient to do it this way:
ρ(p') :=
max
{ρ: p∈S, ∀p∈B(ρ,p')}
In words: the radius of stability is the largest value of ρ such that the ball B(ρ,p') centered at p' is contained in the region of stability S.
Now, condier the specific case where the region of stability S is defined by a performance constraint as follows:
S :=
{p∈P: r(d,p) ≤ r*}
where d denotes the system under consideration and r* is a given critical performance level.
Then in this case the stability radius of system d is as follow:
ρ(d,p') :=
max
{ρ: r(d,p) ≤ r*, ∀p∈B(ρ,p')}
In short:
Info-Gap's measure of Robustness
Stability Radius
α(q,û) :=
max
{α: r(d,u) ≤ r*, ∀u∈U(α,û)}
ρ(d,p') :=
max
{ρ: r(d,p) ≤ r*, ∀p∈B(ρ,p')}
The conclusion is therefore that Info-Gap's measure of robustness is a re-invention of the good old "stability radius".
Remark:
In mathematics and control theory it is often more convenient to use the following alternative definition for the stability radius:
The radius of stability of the system represented by (P,S,I) with respect to the nominal value p' is the radius of the smallest "ball" centered at p' that contains an unstable point. That is, it is the distance from p' to the nearest point in I.
In this case,
ρ(p') :=
inf
{ρ: ∃ p∈B(ρ,p') such that p∈I}
Note the use of "inf" rather than "min" due to the fact that a minimum value for ρ may not exist (eg. if I is an open set).
References
Allende1, H., Moraga, C., and Rodrigo Salas, R. (2001). Neural Model Identification Using Local Robustness Analysis, LNCS 2206, 162-173
Ben-Haim, Y. (1994). Convex models of uncertainty: applications and implications, Erkenntnis, 4, 139-156.
Ben-Haim, Y. (1996). Robust Reliability in the Mechanical Science. Springer, Berlin.
Ben-Haim, Y. (1999). Design certification with information-gap uncertainty, Structural Safety, 2, 269-289.
Ben-Haim, Y. (1999a). Set-models of information-gap uncertainty: axioms and an inference scheme, Journal of the Franklin Institute, 336, 1093-1117.
Ben-Haim, Y. (2001). Information-Gap Decision Theory: Decisions Under Severe Uncertainty, Academic Press, New York.
Ben-Haim, Y. (2001a) Decision trade-offs under severe info-gap uncertainty, 2nd International Symposium on Imprecise Probabilities and Their Applications, Ithaca, New York, 2001.
(PDF file)
Ben-Haim, Y. (2006). Info-Gap Decision Theory: Decisions Under Severe Uncertainty, Elsevier, Amsterdam.
Ben-Haim, Y. (2007). FAQs about Info--Gap. (PDF file)
Ben-Haim, Y. (2008). Info-Gap Economics: An Overview. Working paper, (PDF file)
Ben-Haim, Y and Demetzis, M. (2008). Confidence in Monetary Policy, DNB Working Paper No. 192. (PDF file)
Ben-Tal, A., Nemirovski, A. (1998). Robust Convex Optimization. Mathematics of Operations Research 23, 769-805
Ben-Tal, A., Nemirovski, A. (1999). Robust solutions to uncertain linear programs. Operations Research Letters 25, 1-13.
Ben-Tal, A. and Arkadi Nemirovski, A. (2002). Robust optimization -- methodology and applications, Mathematical Programming, Series B 92, 453-480
Ben-Tal A., El Ghaoui, L. and Nemirovski, A. (2006). Mathematical Programming, Special issue on Robust Optimization, Volume 107(1-2).
Ben-Tal A., Golany B., and Shtern S. (2005). Robust multi-echelon multi-period inventory control, European Journal of Operational Research, 199 (3), 922-935
Ben-Tal, A., Boyd, S., Nemirovski, A.(2006). Extending the scope of robust optimization: Comprehensive robust counterparts of uncertain problems, Mathematical Programming 107, 63-89.
Ben-Tal A., El Gaoui L., Nemirovski A. (2009). Robust Optimization, Princeton University Press, Princeton.
Brook, A.W., and Durlauf, S.N. (2005). Local Robustness Analysis: Theory and Application, Journal of Economic Dynamics and Control, 29(11), 2067-2092.
Burgman M (2007) Info-gap: a user's evaluation of info-gap, SRA 2007. ( PDF file)
Burgman M (2008). Shakespeare, Wald and decision making under uncertainty. Decision Point, 23, p. 10. ( PDF file)
Burgman, M.A., Wintle, B.A., Thompson, C. A., Moilanen, A., Runge, M.C. and Ben-Haim, Y. (2008). Reconciling uncertain costs and benefits in Bayes nets for invasive species management, ACERA Endorsed Material: Final Report, Project 0601 - 0611.
(PDF file)
Carmel,Y. and and Yakov Ben-Haim, Y. (2005). Info-Gap Robust-Satisficing Model of Foraging Behavior:
Do Foragers Optimize or Satisfice?, The American Naturalist, 166(5), 634-641.
Carota, C. (1996). Local robustness of Bayes factors for nonparameteric alternatives, IMS Lecture Notes, Monograph Series, 29, 283-291.
Cornuejols, G. and Reha Tütüncü, R. (2006). Optimization Methods in Finance,
Cambridge University Press.
Cozman, F. (1997). Robustness analysis of Bayesian networks with local convex sets of distributions, Proceedings of the Thirteenth Annual Conference on Uncertainty and Artificial Intelligence, Rhode Island, August 1-3.
Croux, C., and Dehon, C. (2003). Estimators of the multiple correlation coefficient: Local robustness and confidence intervals, Statistical Papers, 44(3), 315-334.
Dembo, R. (1991). Scenario optimization, Annals of Operations Research, 30(1), 63-80.
Fox. D.R., Ben-Haim, Y., Hayes, K.R., McCarthy, M.A., Wintle, B., and Dunstan, P. (2007). Info-gap approach to power and sample size calculations, Environmetrics, 18, 189-203.
Hall, J. and Ben-Haim, Y. (2007). Making Responsible Decisions (When it Seems that You Can't). (FDF file)
Hall, J. and Harvey, H. (2009). Decision making under severe uncertainty for flood risk management: a case study of info-gap robustness analysis. Eighth International Conference on Hydroinformatics, (January 12-16, 2009, Concepcion, Chile)
(PDF file)
Halpern, B.S., Regan, H.M., Possingham, H.P. and McCarthy, M.A. (2006). Accounting for uncertainty in marine reserve design, Ecology Letters, 9, pp. 2-11.
Kouvelis P. and Yu G. (1997). Robust Discrete Optimization and Its Applications, Kluwer.
Davidovitch, L. and Yakov Ben-Haim, Y. (2008). Profiling for crime reduction under severely uncertain elasticities, Working paper, (PDF file)
McCarthy, M.A. and Lindenmayer, D.B. (2007). Info-Gap Decision Theory for Assessing the Management of
Catchments for Timber Production and Urban Water Supply, Environmental Management, 39, 553-562.
McDonald-Madden, E., Baxter, P.W.J., and Possingham, H.P. (2008). Making robust decisions for conservation with restricted money and knowledge, Journal of Applied Ecology, 45(6), 1630-1638.
Milne, W.E., and Reynolds, R.R. (1962), Fifth-order methods for the numerical solution of ordinary differential equations, Journal of the ACM, Vol. 9 No. 1, pp. 64-70.
Moilanen A, Runge M.C, Elith J, Tyred A, Carmel Y, Fegraus E, Wintle B.A, Burgman M, Ben-Haim Y (2006). Planning for robust reserve networks using uncertainty analysis. Ecological Modelling, 199, pp. 115-124.
Paice, A.D.B., and F. R. Wirth, F.R. (1998). Analysis of the local robustness of stability
for flows. Mathematics of Control, Signals, and Systems, 11(4), 289-302.
Regan, H.M., Ben-Haim, Y., Langford, Wilson, W.G., Lundberg, P., Adelman, S.J., and Burgman, M.A., (2005). Robust decision-making under severe uncertainty for conservation biology, Ecological Applications, 15(4), pp. 1471 - 1477.
Resnik, M.D. (1987). Choices: an Introduction to Decision Theory, University of Minnesota Press, Minneapolis, MN.
Rustem B. and Howe M.(2002). Algorithms for Worst-case Design and Applications to Risk Management, Princeton University Press.
Sims, C. (2001). Pitfalls of a minimax approach to model uncertainty. American Economic Review, 91, 51-4.
Sniedovich M. (1979). On the reliability of reliability constraints, pp. 102-126 in Reliability in Water Resources Management, E.A. McBean and K.W. Hippel, eds., Water Resources Publications, Fort-Collins, Colorado.
Sniedovich, M. (2006a). What is wrong with Info-Gap? An Operational Research perspective, Working paper No. MS-1-06, Department of Mathematics and Stratistics, The University of Melbourne, 2006. (PDF file)
Sniedovich, M. (2006b). Eureka! Info-Gap is Worst-Case (Maximin) in Disguise, Working paper No. MS-2-06, Department of Mathematics and Stratistics, The University of Melbourne, 2006. (PDF file)
Sniedovich, M. (2007a). The art and science of modeling decision-making under severe uncertainty, Decision Making in Manufacturing and Services, 1(1-2), 111-136.
Sniedovich, M. (2007b). The Two-Envelopes Paradox: A Primer for Dummies, Working paper No. MS-TE-07, Department of Mathematics and Stratistics, The University of Melbourne. (PDF file)
Sniedovich, M. (2008a). Wald's Maximin Model: a Treasure in Disguise!, Journal of Risk Finance, 9(3), 287-291.
Sniedovich, M. (2008b). Anatomy of a Misguided Maximin/Minimax Formulation of Info-Gap's Robustness Model, Working Paper No. MS-04-08, Department of Mathematics and Statistics, The University of Melbourne.
(PDF file)
Sniedovich, M. (2008c). The Mighty Maximin, Working Paper No. MS-02-08, Department of Mathematics and Statistics, The University of Melbourne.
(PDF file)
Stewart, A.J. (1994). Local robustness and its application to polyhedral intersection, International Journal of Computational Geometry and Applications, 4(1), 87-118.
Wald, A. (1939). Contributions to the theory of statistical estimation and testing hypotheses, The Annals of Mathematics, 10(4), 299-326.
Wald, A. (1945). Statistical decision functions which minimize the maximum risk, The Annals of Mathematics, 46(2), 265-280.
Wald, A. (1950). Statistical Decision Functions, John Wiley, NY.
Journal of the Society for Industrial and Applied Mathematics, Vol 8 No. 3, pp. 537-540.
Yohai, V.J. (1997). Local and global robustness of regression estimators, Journal of Statistical Planning and and inference, 57, 73-92.
Zlobec S. (2001) Nondifferentiable optimization: Parametric programming, in Encyclopedia of Optimization, Floudas C.A and Pardalos, P.M. editors, Springer.
Sniedovich, M. (2012) Fooled by local robustness, Risk Analysis, in press.
Sniedovich, M. (2012) Black swans, new Nostradamuses, voodoo decision theories and the science of decision-making in the face of severe uncertainty, International Transactions in Operational Research, in press.
Sniedovich, M. (2011) A classic decision theoretic perspective on worst-case analysis, Applications of Mathematics, 56(5), 499-509.
Sniedovich, M. (2011) Dynamic programming: introductory concepts, in Wiley Encyclopedia of Operations Research and Management Science (EORMS), Wiley.
Caserta, M., Voss, S., Sniedovich, M. (2011) Applying the corridor method to a blocks relocation problem, OR Spectrum, 33(4), 815-929, 2011.
Sniedovich, M. (2011) Dynamic Programming: Foundations and Principles, Second Edition, Taylor & Francis.
Sniedovich, M. (2010) A bird's view of Info-Gap decision theory, Journal of Risk Finance, 11(3), 268-283.
Sniedovich M. (2009) Modeling of robustness against severe uncertainty, pp. 33- 42, Proceedings of the 10th International Symposium on Operational Research, SOR'09, Nova Gorica, Slovenia, September 23-25, 2009.
Sniedovich M. (2009) A Critique of Info-Gap Robustness Model. In: Martorell et al. (eds), Safety, Reliability and Risk Analysis: Theory, Methods and Applications, pp. 2071-2079, Taylor and Francis Group, London.
.
Sniedovich M. (2009) A Classical Decision Theoretic Perspective on Worst-Case Analysis, Working Paper No. MS-03-09, Department of Mathematics and Statistics, The University of Melbourne.(PDF File)
Caserta, M., Voss, S., Sniedovich, M. (2008) The corridor method - A general solution concept with application to the blocks relocation problem. In: A. Bruzzone, F. Longo, Y. Merkuriev, G. Mirabelli and M.A. Piera (eds.), 11th International Workshop on Harbour, Maritime and Multimodal Logistics Modeling and Simulation, DIPTEM, Genova, 89-94.
Sniedovich, M. (2008) FAQS about Info-Gap Decision Theory, Working Paper No. MS-12-08, Department of Mathematics and Statistics, The University of Melbourne, (PDF File)
Sniedovich, M. (2008) A Call for the Reassessment of the Use and Promotion of Info-Gap Decision Theory in Australia (PDF File)
Sniedovich, M. (2008) Info-Gap decision theory and the small applied world of environmental decision-making, Working Paper No. MS-11-08
This is a response to comments made by Mark Burgman on my criticism of Info-Gap (PDF file )
Sniedovich, M. (2008) A call for the reassessment of Info-Gap decision theory, Decision Point, 24, 10.
Sniedovich, M. (2008) From Shakespeare to Wald: modeling wors-case analysis in the face of severe uncertainty, Decision Point, 22, 8-9.
Sniedovich, M. (2008) Wald's Maximin model: a treasure in disguise!, Journal of Risk Finance, 9(3), 287-291.
Sniedovich. M. (2008) The Mighty Maximin! (PDF File)
This paper is dedicated to the modeling aspects of Maximin and robust optimization.
Sniedovich, M. (2007) The art and science of modeling decision-making under severe uncertainty, Decision Making in Manufacturing and Services, 1-2, 111-136. (PDF File) .
Ben-Haim's response confirms my assessment of Info-Gap. It is clear that Info-Gap is fundamentally flawed and therefore unsuitable for decision-making under severe uncertainty.
Ben-Haim is not familiar with the fundamental concept point estimate. He does not realize that a function can be a point estimate of another function.
So when you read my papers make sure that you do not misinterpret the notion point estimate. The phrase "A is a point estimate of B" simply means that A is an element of the same topological space that B belongs to. Thus, if B is say a probability density function and A is a point estimate of B, then A is a probability density function belonging to the same (assumed) set (family) of probability density functions.
Ben-Haim mistakenly assumes that a point estimate is a point in a Euclidean space and therefore a point estimate cannot be say a function. This is incredible!
A formal proof that Info-Gap is Wald's Maximin Principle in disguise. (December 31, 2006)
This is a very short article entitled Eureka! Info-Gap is Worst Case (maximin) in Disguise! (PDF File)
It shows that Info-Gap is not a new theory but rather a simple instance of Wald's famous Maximin Principle dating back to 1945, which in turn goes back to von Neumann's work on Maximin problems in the context of Game Theory (1928).
A proof that Info-Gap's uncertainty model is fundamentally flawed. (December 31, 2006)
This is a very short article entitled The Fundamental Flaw in Info-Gap's Uncertainty Model (PDF File) .
It shows that because Info-Gap deploys a single point estimate under severe uncertainty, there is no reason to believe that the solutions it generates are likely to be robust.
A math-free explanation of the flaw in Info-Gap. ( December 31, 2006)
This is a very short article entitled The GAP in Info-Gap (PDF File) .
It is a math-free version of the paper above. Read it if you are allergic to math.
If your organization is promoting Info-Gap, I suggest that you invite me for a seminar at your place. I promise to deliver a lively, informative, entertaining and convincing presentation explaining why it is not a good idea to use — let alone promote — Info-Gap as a decision-making tool.
Here is a list of relevant lectures/seminars on this topic that I gave in the last two years.
Disclaimer: This page, its contents and style, are the responsibility of its owner and do not represent the views, policies or opinions of the organizations he is associated/affiliated with.
 A PDF version is available.
A PDF version is available. 
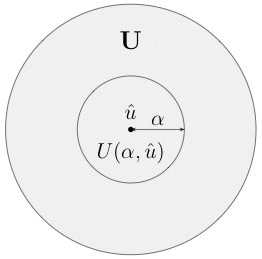
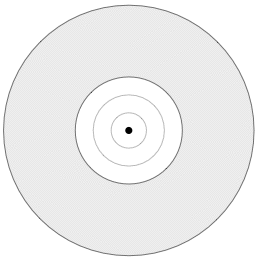


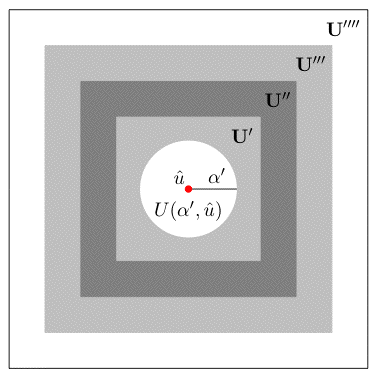




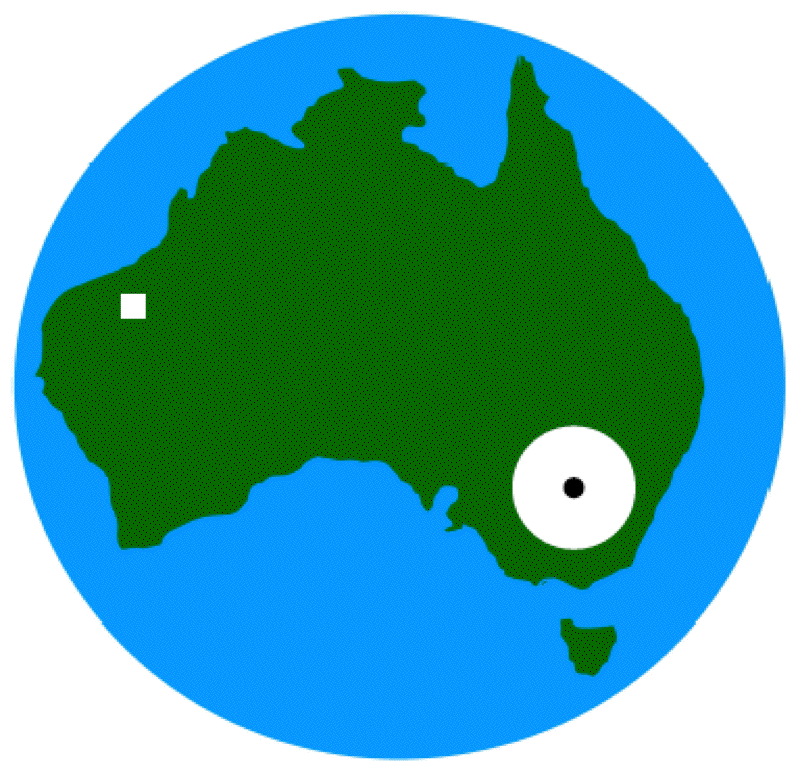
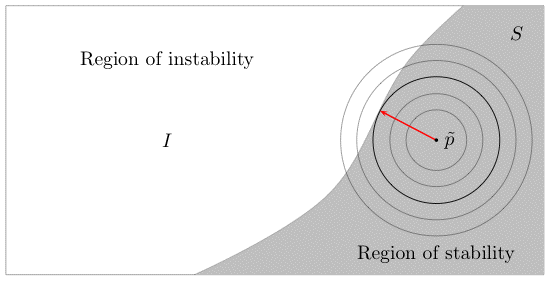
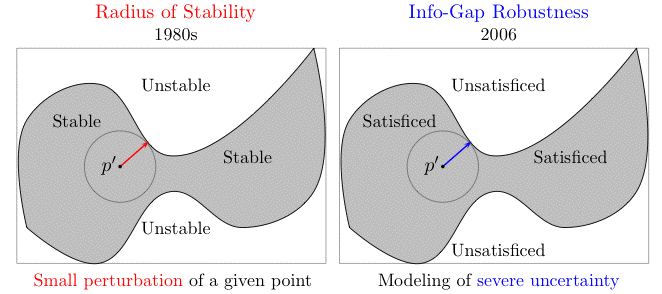

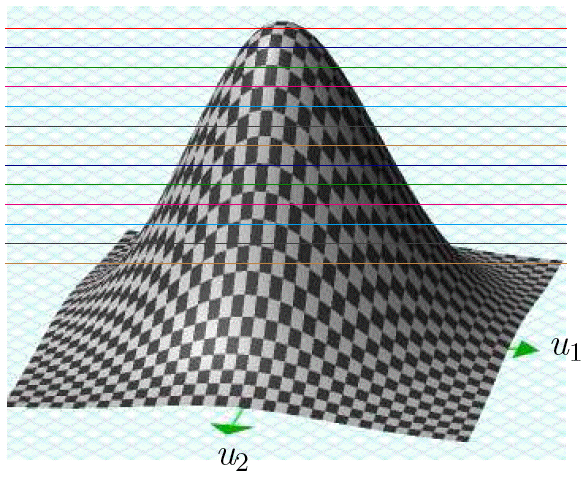
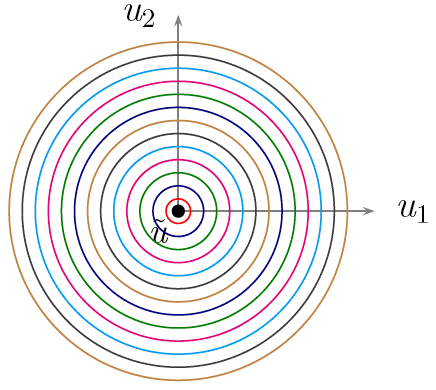
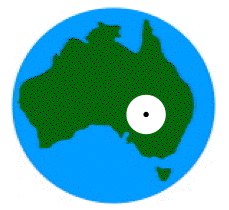



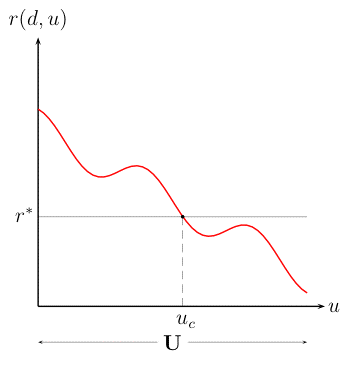
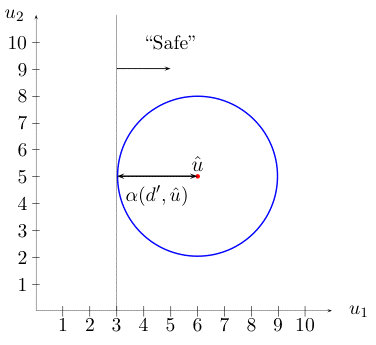
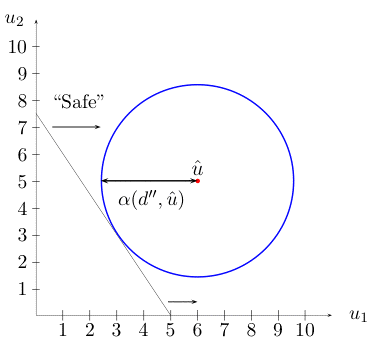

 You need to replace the old climate control system in your greenhouse. The main function of this system is to control the temperature, t, in the greenhouse. Several products in the market fit the bill so, your task is to decide which of these suits your needs best.
You need to replace the old climate control system in your greenhouse. The main function of this system is to control the temperature, t, in the greenhouse. Several products in the market fit the bill so, your task is to decide which of these suits your needs best. The new climate control system will be used in a strawberry greenhouse where the nominal temperature, tn, is known. The new system must maintain the temperature in the greenhouse at this level. However, the system must also be able to cope well with deviations from this nominal value, and preference will be given to systems that can cope well with large deviations -- subject to a performance requirement.
The new climate control system will be used in a strawberry greenhouse where the nominal temperature, tn, is known. The new system must maintain the temperature in the greenhouse at this level. However, the system must also be able to cope well with deviations from this nominal value, and preference will be given to systems that can cope well with large deviations -- subject to a performance requirement.